
cs143
introduction
- interpreter:online
- takes the program and the data you need,then give the output.
- compiler:offline
- it takes the program and give the executable(different type),this executable then takes data and run
- fortran I(the first compiler)
- lexical analysis
- parsing
- semantic analysis
- optimization
- code generation
- lexical analysis is not trivial,it divides sentence into words(tokens)
- parsing is diagramming the sentence(it’s a tree)
- sematic analysis understand the meaning(仅能做到非常有限的,主要检测不一致性)
- optimization(很多时候不显然):
- x=y*0<=>x=0,不对,当x为浮点数的时候NAN不满足
- why there are so many language:
- different use and domain(which needs different feature):scientiffic computation,business application,system programming
- why are there new programming language:
- widely used languages are slow to change,thus hard to fit the new domain
- it’s easy to start a new language
- the main cost is to train programmer,so once the improve greater that cost,they’ll change
overview of COOL
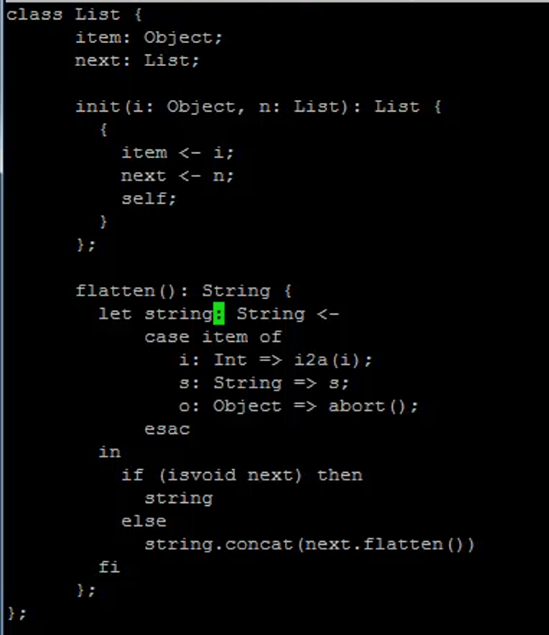
class Main{ |
- inherits后可以用self指代自己,所有methods都是global的,attributes都是local的
- 方法仅有一个表达式的时候不用加括号
IO.in_string().concat("\n")- string to integer:A2I.a2i/i2a
- include library:just involve the file
- if then else fi
- =为比较运算符,<-才是赋值用
from doc
- all methods have global scope while variables are local
- features(attributes and method)must start with lower case
- 默认继承object类(inheritance graph)
- conforms:the child object be used in the place of parent object
- if c inherits from p,then
type checker make sure the (dynamic type conforms the static)
- if c inherits from p,then
- SELF_TYPE:指代当前对象的type
- void:like NULL in C,not the type
- dispatch(i.e method call):one way <expr>@<type>.method()
- join:the least element of conforms(继承树的最近公共祖先)
- semicolon is used to as terminators of a list
- let:前面定义的变量全部绑定好后算in后面的expr
- case provide a method to do runtime type check
case <expr0> of |
lexical analysis
identify tokens in the input string(not only divide,but recognize the class)and send the pair<class,substring>to the parser
lingo:the recognized substring->lexme the pair->token pattern:a description the lexme may look like
- identifier:strings with digit and letter,start with letter
- integer: a non-empty string of digits
- keyword: reserved string like if,else,while,typically one for each word
- whitespace: a non-empty string of blank newline and tab
some principle:
- the scan behave from left to right,and need to look ahead(e in else needs this to comfirm the keyword)
regular and formal languages
- regular languages(finite automate recognizable)
def:let alphabetbe the set of characters,the formal language is the string consists of these characters
compound of regular expressions:single characters epilon union concatenation iteration - formal languages
syntax vs semantic:many to one
many expressions have the same meaning but one exp must just corespond to one
it also leaves space for optimization
L function maps syntax to semantic - some abbrevation
‘e’? stands for optional
lexical specification
step1:write a rexr for the lexmes of each token class
step2:construct R,matching all lexmes of all classes(just the union)
step3:
addition:
- maximal munch:when two different prefix are valid,choose the longer one (= and ==)
- chose the one listed first:when one prefix can be two token class(if in keywords or identifiers)
- error class:complement of the others,give it the least priority
finite automata
参考计算理论相关笔记
DFA通常执行更快,NFA更紧凑(空间更小)
implementation
DFA:simply implemented as a 2D array where T[i,a]=j mean that state i convert to j when input is a
NFA:put the set of state
it’s very common to see duplicated row so we can use pointers to store just one copy of them
PA1
- cool不支持在块中直接声明局部变量,所以要用let
- 超过一句的函数体放在block中
- ;用于分割表达式,{}用于把多个语句变成一个表达式
- 加分号的原则:
- 同一个{}中的多个表达式
- if/while/let与其后表达式之间
- 方法体,if/while/let这些地方仅允许单个表达式
- 放方法接口在父类里面
PA2(edx version)
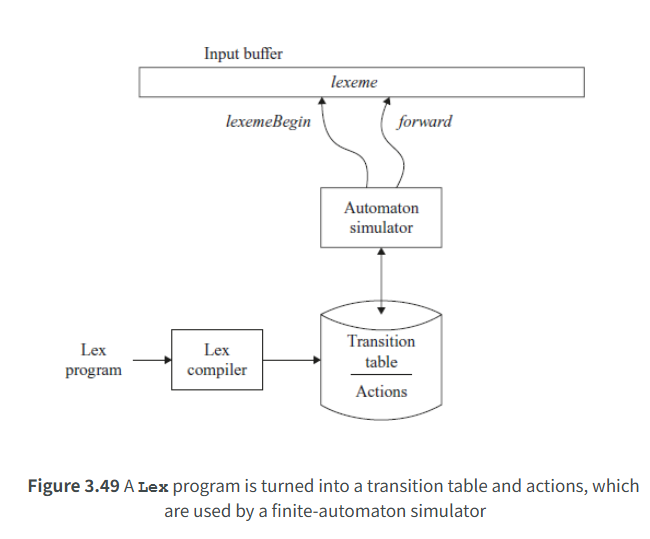
flex from pdf
tools for generating the lexical analyser based on the written rules
%{ |
declarations and user subrountines are optional and allow you to write C
definitions also optional,e.g: DIGIT [0-9]
rules:
- 同时满足多个表达式的选择match最多的
- match一样就选择最先出现的
- look ahead:一种方法是设置全局变量,要用的时候设置为true,也提供了语法糖
- programs tend to have the keywords duplicated,so maintain a string table can help
- unescaped newline:在多行字符串字面量中单纯的\n不合法,\n才合法(显示效果如下)
this is\ |
flex from doc
- pattern
- . matches any char except the newline,if using ^,matches newline
- <<EOF>> an end of file
- 在character class 中,除\ - ] ^外都只是表面字符
- match
- once matched,the text is available in global variable yytext(pointer or array),and its length in yyleng
- if no match found,default will just copy the text
- start conditions
在不同的语法上下文启动不同的规则
<INITIAL,STRING>. //只有在当前处于两状态之一的时候后面的code才生效 |
state在definition region 使用%s%x(仅激活显式标注)声明
- <<EOF>> 是一种规则而不是字符
- 语法要求严格:pattern后要有空格,前不能有!!!
- \n(0x0A)表示一个字符,普通换行符
- \n(+n)(0x5C+0x6E)表示两个字符,前一个字符转义反斜杠用的
- \n视觉上是这样,也有可能表示(0x5C+0x0A),字符串中的合法换行
/* |
dragon book first part
- word:
boldface(黑体) - token:<tokenname,attribute_value(optional)>,we shall assume the value be only one(maybe struct pointer)
- e.g:the token for identifier,maybe the type,location…
- when the rest can’t be matched,some strategies to make it continue(not for correct,but more scan to find mistake)
- panic mode:continue to delete the char(also transition,substitution)
- a subsequence of a string is the string delete arbitrary letter forms banana -> baan
- 每一个pattern写一个NFA,最后从开始状态到每个子NFA来一个空转移
- 最长匹配原则要求在读到无出边的时候回溯至最后一个接收状态
- dead state 走向空集的,工程实践就是不画出来(可能有很多,统一成一个信号)
- look ahead operator,,仅匹配在紧挨着2的1,不匹配2,直接将/视为空转移
- endpoint
- if no lookahead:just the last accept
- if exist x/y,the end state s has an ,start to s build x,s to some build y,and x as long as possible
- pattern空转移在NFA转DFA的时候就被吸收了,lookahead要有标识
top-down parsing
introduction to parsing
- finite automaton only be able to handle mod k problem(string with odd 1)
| state | input | output |
|---|---|---|
| lexical analysis | string of characters | string of tokens |
| parsing | string of tokens | parse tree |
- the role of parser:describe valid token and distinguish it from invalid
- e.g
EXPR -> if EXPR then EXPR else EXPR fi |
derivations
- definition:a sequence of production leading to string only contains terminal
- it can be drawn as a tree
- parse tree has non-terminal in non-leaf and terminal in leaf
- inorder traversal of leaf form the output
- it shows the association of operation
- leftmost and rightmost derivation:every time replace the left(right) most non-terminal
ambiguity
- a grammer is ambiguous if it has more than one parse tree for a string
- equal to have more than one left(right)most derivation
solution to ambiguity
- straightforward:just rewrite the grammer
- eg1:id*id+id just introduce more state and let one state do one operator
- eg2:IF THEN ELSE 匹配
//solution to eg1 |
- however there’s no automatic way to rewrite it,so common practice is to form some rules
- association:leftassociation of * for example
- precedence: the order of assiciation list in practice
syntax directed translation
error handling:
- should report error accurately and clearly,recover from error quickly,not slow down compile of correct code
- some approach:
- panic mode:discard a single token until one with a clear role is found
- use the production:
E->int|E+E|error
- use the production:
- error production:specify the common error in the production
5 x E->E E - error recovery:find a correct nearby program(by insertion or deletion,searching)
- panic mode:discard a single token until one with a clear role is found
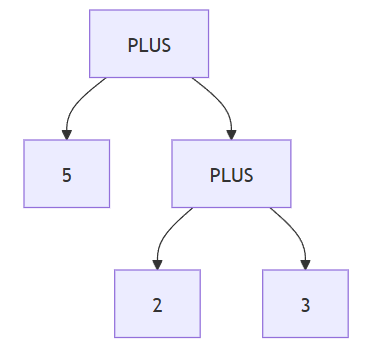
abstract syntax tree(AST):just a parse tree that ignores some details
- e.g:5+(2+3),ignore single-successor,the parenthesis
recurssive descent parsing
-
some what similar to depth first search
- try each production in order,when producing terminal in current left,compare,if mismatched return to the next
- only find itself on the wrong track when mismatch or terminated before the input terminate
-
algorithm
bool term(TOKEN TOK){return *next++=TOK;} |
- large limitation:can only be sufficient for any non-terminal only one production succeed
we can left factor the grammer to meet the demand - left recurssion
some thing like this
in general
rewrite it as
systematic algorithm:

PA3
%type <member_name> x y z//the attributes of x,y,z is stored in member_name member of the union
bison
chapter1
- CFG has many subclass:LR(1),LALR(1),LR(0)…
- it’s optimized on LR(1):从左到右扫描,构造最右推导的逆过程,lookahead only one
- 历史原因,用的是LALR(1),some strange confict,to avoid specify IELR(1) or canonical LR(1)
- deterministic:the next production applied is determined by the preceding input and finite portion of remaining
- input corresponding to terminal symbol->token,non-terminal->grouping
- semantic values:e.g the calculator expr has values which is a number,the program has a tree as the value
- semantic actions:
expr: expr '+' expr { $$ = $1 + $3; } ;when recognized execute the code
chapter2:example
/* Reverse Polish Notation calculator. */ |
compile:bison file.y->file.tab.c,再使用C编译器编译
chapter3
- outline of bison grammer
%{ |
-
there’s no need to declare character token kind or literal string token unless you need semantic value data type,association or precedence
-
just empty component means empty rules,%empty for explicit
-
in bison,use left recurssion
-
支持多种语义值类型的方法:
- modern way:use type tags directly
%token <int> INT - traditional:显式定义union,
%union{int ival;} %token ival INT - 结构体选
- modern way:use type tags directly
-
C code refer to the sematic value:
exp[result]:exp[left] '+' exp[right]{ |
chapter4
- int yyparse(void),invoke parse,return 0 when succeed,1 when invalid input,2 when memory exhausted
- use %parse-param{}can pass parameters to yyparse when reentrant
- use -d option when using bison to create .h file
- if union is used like above,in yylex
yylval.ival=value; |
describe AST:接口描述语言(IDL),描述AST类,list容器,访问接口
when encounter an error:yyerror would be invoked
the bison way to recover from error:
it generates error token each time,when you define the rule include it,parsing will continue
-
step1:pop parsed stack until find a state can shift error
-
step2:shift error
-
step3:discard input until the lookahead can work
-
多字符运算符要用token名
-
cpp区分’self’字符常量,"self"多字符字符串
-
一元运算符通常右结合
-
LET (OBJECTID ‘:’ TYPEID [ASSIGN expr])+ IN expr 递归:右递归带着尾
tail: |
- list式的错误修复:item中有错误,能跳过并给该对象一个合法的安全值
- 逻辑:list分隔符统一在item中处理,list仅负责拼接
- 没有关于letbinding的可用接口可以自己写!!!(declare a struct in declaration are allowed)
- 嵌套设计:前缀和后缀不参与递归构造(单独抽象一个中间的列表出来),左结合or右结合?
- yyerror:报错
- yyerrok:手动处理后继续解析
bottom-up parsing |
predictive parsing:by just lookahead tokens to determin the only production
it accept LL(k) grammer,i.e:left-to-right-scan leftmost derivation k tokens of lookahead
need to left factor(提出公共部分,不同部分由另一个变元决定) the grammer
T->int|int *T|(E) |
parsing table
- next input
leftmost non-terminal
term:rhs of production - use:every time look up table,stack record the frontier(leftmost non-terminal)
reject on error state,accept when input finishes and no non-terminal
//algorithm |
first sets
first(t)={t} where t is terminal
or like the before(prefix can be eliminated)
follow sets(dollar indicates char )
- intuition
- algorithm
$ dollar \in follow(S) $
for each production
for each production
parsing table
- the only reliable method to judge if it’s LL(1), is to check whether the table has two entries in one position
- rules
- for each terminals
- for
- if $ \epsilon \in first(\alpha)\text{ and dollar} \in \text{follow(A)},T[A,dollar]=\epsilon $
以上内容实际上属于自顶向下parsing
bottom-up parsing:reduce the input string to the start symbol invert productions
- reverse of the rightmost derivation(from another direction,just production)
- this leads to a fact , be one stage,reduction be ,then must be terminals
shift-reduce parsing
use vertical bars divide string,left been seen
- shift:move | one token to the right
- reduce:apply inverse to the right most of left string
bottom-up parsing||
-
handles
we want to reduce only when the result of reduction can still be reduced to the start symbol
handles:a string that can be reduced and allows further reduce to the start symbol
fact:the handles in the shift reduce parsing always appear on the right-most of left part(stack) -
recognizing handle
no efficient way,just heuristics way on SLR(k)
viable prefix: is a viable prefix if is a state of shift reduce parser
for any SLR grammer,viable prefix is a regular language
item: a production with ‘.’ e.g:T->(E) generate T->.(E) T->(.E) … of four total- the only item for x-> is x->. ,item also called LR(0) items
- it means that e.g:T->(.E) the stack already has ‘(’ ,and hope to see ‘E)’
generalizaion:when stack has
-
recognizing viable prefix
we can build an NFA- add
- for item
- if there is production
- every state of NFA be the accept state
- is the start state
-
valid items
an item I is valid if for viable prefix ,if the DFA recognize viable prefix terminated by input in accept state contain I -
SLR(simple LR) parsing

if the rules above can’t resolve problem,it’s not SLR grammer(if so,we can use precedence declaration(actually confict solution)) -
improvement

where the goto just the transition function of DFA,action maps current state to the taken action
actually LR(1) is more powerful than SLR(1),which build the lookahead into the item(LR(0)item,lookahead)
semantic analysis & type
semantic analysis
semantic analysis is the last period of front-end phase,detect all the remaining errors from previous two stage
much of the semantic analysis can be done by more than once of recursive descent of AST(just process some part,when return to it again,finish)
-
scope:the scope of an identifier is the portion of the program where it’s accessible
- static scope:scope only depends on the code context instead of runtime behaviour,mainstream
- dynamic scope:the closest enclosing binding in the execution
-
symbol table:a data structure that tracks current bindings of identifiers
can be implemented by stack:enter_scope,add,find,check_if_defind,exit
for class definition(can be used before definition):scan more than once

type
- type checking
type:a set of values and a set of operations on these values
the goal of type checking(verify fully typed program)is to ensure that operations are used with correct type
type inference:fill the missing type information(use rule of inference:if hypothesis are true,conclusions are true)
vdash means it’s provable
type checking proof has the form of AST - type environment:function from Objectidentifier to type
free variable:variable that are used in a expression without its definition within the same expr
under the O environment,it’s provable that e has type T
where: O[T/x]means that the environment is modified,when input is X,return T(implemented by symbol table)
type environment are passed down from top to down,compute from leaves to root of AST - subtyping
if x inherits y,,this allows the child assigned to the parent
for IF statement,the return type can be either branch since we don’t know which branch will be executed
so we need to find least upper bound for two statement(lub(x,y)) - typing method
method and objectidentifiers are in different namespace(so can be of same name)
表示C中有一个函数f,返回值类型为最后一个
type of variable are modeled by environment
- implementation of type checking
COOL TC can be one with one pass type checking over AST
type environment be passed from top to down,types are passed bottom up

type checking ||
type systems and expressiveness
static type(compile time) can disallow some correct program
some solution:dynamic type(run time),more expensive static type
methods can be redefined with same type(重写方法必保持同类型签名)
-
SELF_TYPE
it’s a static type,but not a name of class
e.g:
Stock inherits Counter(which has a method inc return type Counter)
(new Stock).inc() has static type Counter,can’t be assigned to Stock stuff
instead we declare return type to be SELF_TYPE(automatically infer)
it refers to the occurrence of SELF_TYPE in C -
extend
always need to be false(can be true,but we need to think it false for safe) -
extend lub
-
where the SELF_TYPE are not allowed
class definition
static dispatch:M@T.func()
the type of formal parameter of function(can form a normal type be a subtype of SELF_TYPE) -
rules
the rules for dispatch and static dispatch need to change
e@E.f(T),if the return type in the signature is SELF_TYPE,just return the same type of e(not must be E)
error recovery
recover from type error
strategy1:assign Object to every ill-typed
strategy2:assign No_type to them(No_type is the subtype of every type,break the tree structure,a little complicated)
runtime environment
runtime resources
roughly speaking,the program can be divided into code and other
compilers need to:generate code,orchestrate(协调) the use of data area with high speed and correctness
assumption:execution is sequential(no concurrency),procedure return give back the control to where it was called(no exception)
- activation
an invocation of procedure P is the activation of P
the lifetime of an activation:all the steps execute in the P and P calls
the lifetime of a variable: portion of execution where it’s defined
lifetime is dynamic concept while scope is the static concept
the second assumption make sure the P calls Q means Q inside P(properly nested),this can form an activation tree(can use stack) - activation records
the information needed to manage an activation is called activation records(AR),also called frame
it contains the information for callee to execute,for caller to resume
typically contains the return value,actual param,pointer
the AR layout and code depend on each other,so we need to design at the same time
将返回值放在栈帧的开头有助于其调用者通过固定的offset直接访问(说是栈但是并不会马上弹出,现代编译器更多使用寄存器)
storage
globals:fixed memory address,variables are statically allocated
heap:store dynamically allocated variables
ELF是文件在磁盘中的存储形式
most machine need data to be aligned(8 bits form a byte, 4\8 bytes a word)in word(some allow disaligned with high access cost)
strategy for alignment:just skip the next few byte
stack machine
- stack machine
a simple expression evaluation model
for each operator,pop the operand,compute,then push the result
advantage:no need to specify the location of data,instruction can be shorten(why java bytecode use it) - optimization
store the top n element of stack in register instead(reduce memory access)
just one register helps a lot(called accumulator)
when compute op(e1,e2,e3,…,en),eval e1 to en-1 and store in the stack,eval en and leave in the register,eval operator and update
invarient:the state of stack keep the same before and after evaluate one expression
for simple addition ,3 memory access to 1
code generation
Basic
- simple arithmetic
generate code for stack machine:accumulator in a0,the rest of stack in memory,sp refer to unused stack top(grow to the lowaddress)
MIPS:属于RISC架构,32位,所有操作对寄存器进行
code generation strategy:for each expression,compute the value and store it in the a0,preserve the stack to be the same
不要老是想着用$t1(临时寄存器),在递归调用的过程中可能直接覆盖掉了
stack machine code generation is recurssive,this means we could write it as recursive descent of AST
for IF statement,we need flow control instruction(beq reg1 reg2 label:若reg1=reg2则跳转至标签处)(b label无条件跳转) - funciton and variable
no need for storation of result,for f(x1…xn),push params in the reverse order
we need frame pointer(fp) to the current activation
the AR in the stack:old frame pointer,params(reverse order),return address
calling sequence:instructions to set up the function invocation(jal lable:将下一条的地址存在$ra并跳转至标签处)(jr reg:跳转至reg中的地址处)
frame pointer指的是栈帧的top,整个栈帧一共4n+8 bytes long
for function call:保存old frame pointer,逆序压入所有参数,存返回地址,跳转至定义处
for function definition:更新frame pointer,执行函数体后恢复fp,栈中弹出整个frame,return
对于变量而言:使用frame pointer来存(stack pointer在变,offset 不固定) - temporary
for many operation,previous strategy has so many operation on stack,we could optimize it by storing it on activation record
NT(e),计算e所需要的temporary
我们的栈帧直接在return address 后面再添上temporary即可
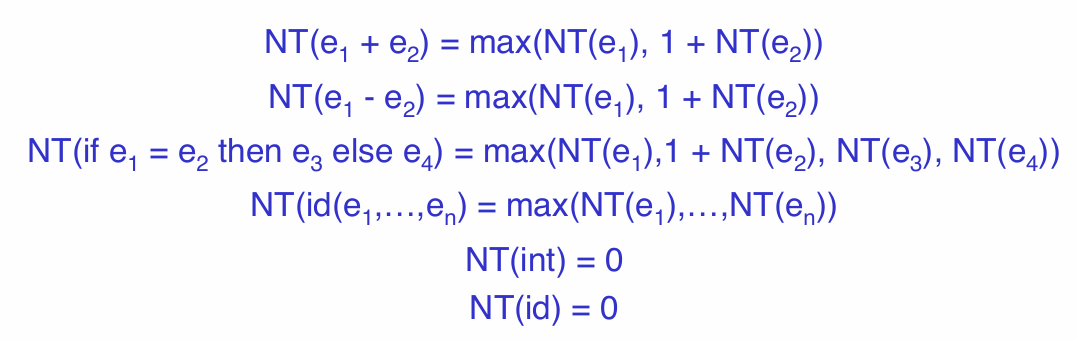
in order to use this strategy:we need a nt indicate where the next available temporary exist
cgen(e1+e2,nt)= |
object
对象其实类似于C中的结构体
object layout in the contiguous memory,each attributes lies in the fixed offset,when a method is invoked,the object is self
layout:class tag(compiler will assign a distinguish integer),size,dispatch pointer,attribute slot
subclass:just extends the attribute slot of parent class(the longer the layout is,the more it has anscestor)
every class has a fixed dispatch table:just an array of entry pointer,fixed offset(can share between different object)
operational semantics
motivation
- we need to specify evaluation rules for every expression(this is the meaning of expressions)
one example:the rules to translate cool program to stack machine,and the rule to evaluate stack machine
why is this not enough:assembly language description can involves irrelavent details(we need complete rules) - ways:
- operational semantics:describe evaluation via execution rules on an abstract machine
- denotational semantics:program’s meaning is a mathematical function
- axiomatic semantics:behaviour described by logical formulae(公式)
notation
environment(E):maps from variable name to memory location store(S):maps from memory location to exact value
S[12/l1]:表示除了l1值为12,其余保持不变
object:X(a1=l1,a2=l2…an=ln) X is class a and l is attribute-location pair
so is the current value of self,if e eval terminate,update store
rules


- operation of new
where the order of attributes satisfy the greatest ancestor(继承关系中越在上面的越先)
D means default initializer

- operation of dynamic dispatch
impl(A,f)=(x,e) where x means the formal params,e means the body of the function
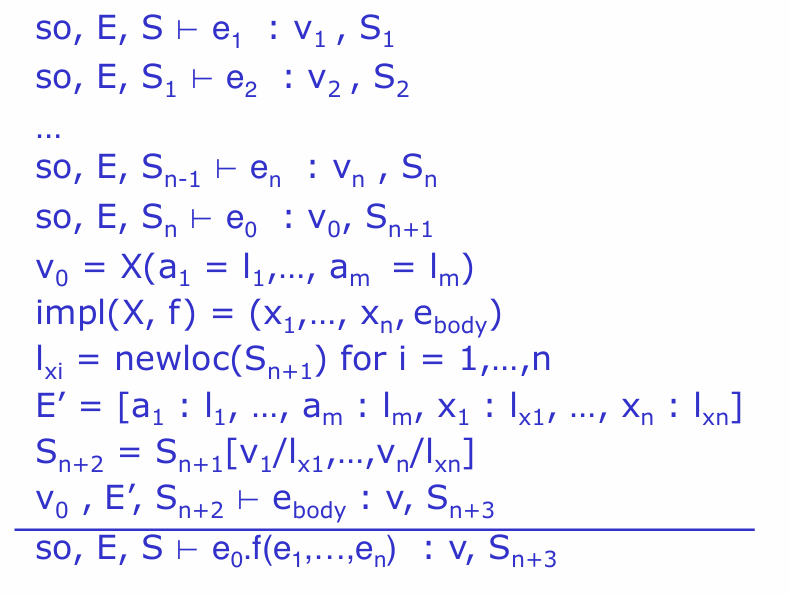
the order of E ensures the hide of outer variable with same name
type checking 保证了不会产生这个类不存在这个方法的情况(但是一些runtime error 没办法)
PA4
object layout:the offset of -4 contains garbage collector(not part of this object),object size and garbage collector field are under the control of runtime system
prototype(也可以指函数声明) object:cool中,在堆上生成新对象的唯一做法就是调用object.copy方法,code generator在data区会生产一个类的skeleton用于copy,这就是prototype
code generation gl:case必须比较最具体的祖先类型
register and calling convension:need to refer when needed
脑子糊了,为了应付学校转而做北大实践课
Intermediate Code & Local Optimizations
intermediate code
实际上可以认为是高层的汇编语言:机器无关,但是能体现出优化的可能.
each instruction: x:=y op z x:= op z(y,z是寄存器或者常数)
basic block:maximum sequence of instructions without lables and jumps inside it(except the begin and the last)
- make sure we cannot jump in or out in the middle
control flow graphs:directed graph with basic block as its node,edge from a to b means the execution pass from a to b
- can represent method
classification of optimization:
- local optimization:carry out inside the basic block
- global optimization:apply to the CFG(control flow graph)
- inter-procedural optimization:across method boundaries
local optimizations
- algebraic optimization
x:=x+0 x:=x*1 x:=y**2(乘方的开销很大) - constant folding
作用于常数的操作可以在编译时就计算出来
有些时候有危险:浮点数在跨平台编译时的舍入误差,解决办法就是将准确计算出的结果存成字符串在那个平台舍入 - flow of control
去掉不可达的basic block,有些时候由于缓存更高效也能提高效率 - static single assignment(SSA) form
每个寄存器都仅仅在赋值操作的左边出现一次 - common subexpression elimination
若x:=rhs是第一次在块当中使用,若两个语句是相同的rhs,直接赋值x - copy propogation
假设满足SSA,有w:=a,后续的a全换成w - dead code elimination
w:=x,然而w在任何地方都没有出现过
peephole optimization
直接在汇编上进行优化
e.g: addiu a0 i addiu a0 j => addiu a0 i+j
global optimization
flow analysis
some simple basic block propagation can be extended to global
but there are situations that the result can be incorrect
- simple principle:to replace a variable x with constant k,we have to be sure that every path to the use of x,the last assignment is x:=k
(non-trivial needs entire analysis of date flow) - this takes several traits:总是要依赖于变量属性,需要全局的知识,保守总是可以接受的
constant propagation

三种表示 bottom constant top
-
the analysis of complicated program can be expressed as a combination of simple rules about the value before and after statement(C(s,x,in)=the value of x before s)
-
rules for merge(x to s):
- if C(pi, x, out) = ⏉ for any i, then C(s, x, in) = ⏉
- C(pi, x, out) = c & C(pj, x, out) = d & d <> c then C(s, x, in) = ⏉
- if C(pi, x, out) = c or ⏊ for all i,then C(s, x, in) = c
- if C(pi, x, out) = ⏊ for all i,then C(s, x, in) = ⏊
algorithm:first set the entry to be Top,all the other to be the bottom,then repeat to use rules to update(until no breaking)
- the analysis of loop
to analize the loop,we need the bottom notation
在循环中,所有点都必须有值(这个值又来自前面的语句),为了打破循环,我们提前假设所有非入口都为bottom 这样就能开始分析与更新 - ordering
规定:
lub(least upper bound):最小的大于所有元素的结果
这样分析可以很清晰地证明算法的终止性:value从bottom开始并且只能向上变,所以最多变2次,算法是线性的
liveness analysis
the value of x is dead if it’s never used otherwise it’s live
- rules
- L(p, x, out) = ∨ { L(s, x, in) | s a successor of p }
- L(s, x, in) = true if s refers to x on the rhs
- L(x := e, x, in) = false if e does not refer to x
- L(s, x, in) = L(s, x, out) if s does not refer to x
algorithm:先全设成false再变(同样具有线性时间收敛的保证)
register allocation
memory hierarchy management
在计算机内存结构中:程序员负责数据在硬盘和主存间的移动,硬件负责主存和缓存之间的移动,编译器负责主存和寄存器之间的移动
通常的中间表示都用了太多的寄存器
idea:temporaries y1,y2可以共用一个寄存器如果在程序的任一点,y1和y2至多只有一个是live的
register allocation
-
the register inference graph(RIG):
根据相应算法计算liveness,然后构建出的关于temporaries的无向图
draw an edge between two nodes if they’re live at one same time
by just coloring the graph(same as allocating the register),we can get answer -
启发式方法
原理:取一个邻边小于k条的点,删去这个点及其边之后的子图若k-colorable,原图也k-colorable
方法:重复删除邻边小于k的点及其边,并将删掉的边入栈,直到只剩一个点;按栈中顺序处理点,每次分配不与相邻点相同的颜色 -
spliting:not k colorable时选择一个候选者f
- 删除f后在剩下的图上涂色,如果候选者的所有相邻点一共用了小于k种颜色,可以直接将f加回去涂色(optimistic coloring)
- 如果不行,开始使用内存存取,通常是栈帧,每次读取操作之前fi:=load fa,写入操作后fi:=store f,fa(每次使用fi给不同名字)
- 重新计算liveness和RIG
-
选择f的方法:最多conficts(就是边)的 较少使用和定义的 避免split内层循环中的
cache management
通过交换循环改善缓存性能:有些编译器能做到
for(i := 1; i < 1000000; i++) |
Automatic Memory Management
introduction
- reachability
an object is reachable if and only if a register contains a pointer to it or a reachable object contains a pointer to it
garbage are non-reachable object - tracing
we need to trace from acumulator and stackpointer
detailed techniques
mark and sweep
when run out off memory,execute the mark and sweep
- mark:
let todo = { all roots } |
- sweep:
(* sizeof(p) is the size of block starting at p *) |
- one problem:we run it when run out of memory,so we have no memory to hold the list(the size of this data structure can be quite large)
- trick to it:the reversal of pointer(从a到b的指针,trverse到b的时候将a到b的指针翻转为b到a的指针,同时在寄存器中保留一个指向a的指针,防止丢失)
- 这种策略可能会导致fragment(可参考csapp相关章节),但是不用移动object
stop and copy
memory is organized into two part,old space for allocation,new space reserved for garbage collector
idea:allocation just increment the pointer,when old space full,just copy all reachable obj to new space and exchange the region
while scan ≠ alloc do |
forwarding pointer to update the pointer between object

- fairly cheap and fast,but for language like cpp/c,object is just not allowed to be moved
reference counting
new ruturn an object with ref=1
when execute x=y,assume x points a,y points b
ref(a)-- |
实行很简单,但是对于互相引用的不可达对象可能无法回收
garbage collection 看起来挺好,但是失去对程序的精细控制,同时会延长运行时间,有时候一直引用一个巨大的数据结构导致内存泄漏(所以记得x=NULL)


