
fundametal of statistics
Distributions Derived From the Normal Distribution
some distribution

- inflection point:拐点 bell curve:正态曲线
- moment generating function:矩生成函数
- 矩生成函数可用于计算分布的矩:关于 0 的第n个矩是矩生成函数的第n阶导数,在 0 处求值。(另一种对概率分布的描述)

- 矩可以视为(moving to average)
chi-square distribution(卡方分布)

- gamma distribution:描述的是等待n个事件发生的时间之和
(),记为()前者为事件次数,后者为单位时间内的的发生率


student’s t distribution

- 自由度为r的t分布,当k<r时,积分收敛,k次矩存在(重尾性)
- T的矩生成函数除了在0均不存在
F distribution

Statistics from Normal Samples

-
n个正态分布的随机变量中取样出来仍服从正态分布:利用MGF 即可证明
-
why 样本方差是除以1/(n-1):
- 最简单的原因,是因为因为均值已经用了n个数的平均来做估计在求方差时,只有(n-1)个数和均值信息是不相关的。而你的第n个数已经可以由前(n-1)个数和均值 来唯一确定,实际上没有信息量。所以在计算方差时,只除以(n-1)(无偏估计)
-
证明思路(该情况下不相关等价于独立)

-
证法(联合MGF分解为分别的MGF乘积)
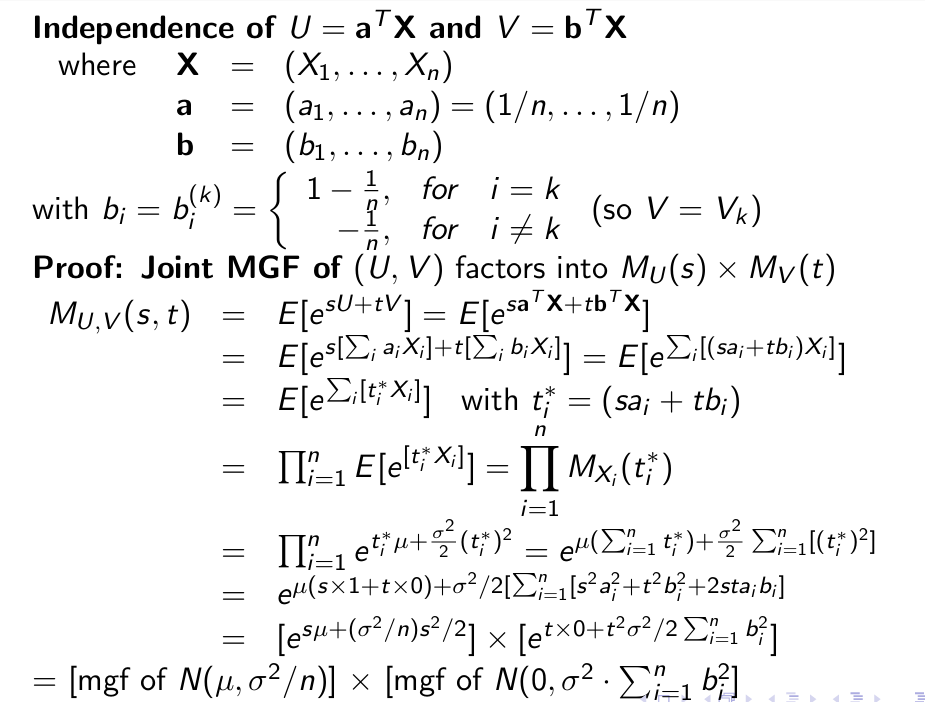
-
证明:从已知的分布出发(n个标准正态分布的平方和)


以上为sp15内容(没video还是太吃操作了)
Introduction to Statistics
-
统计与建模


-
大数定理告诉我们:当实验的次数足够的多的时候,对每次实验结果的随即变量求均值将可由正态分布极好得近似
-
asymptotic confidence interval (渐进置信区间)
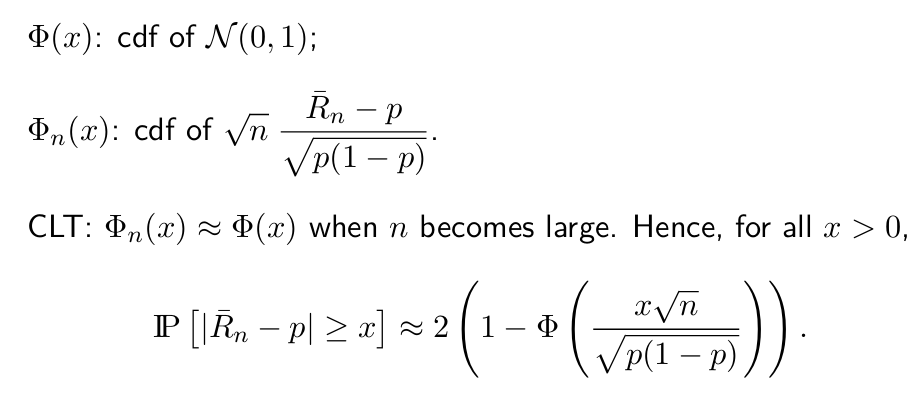


-
霍夫丁不等式

不同类型的收敛
- (几乎处处收敛和依据条件收敛)
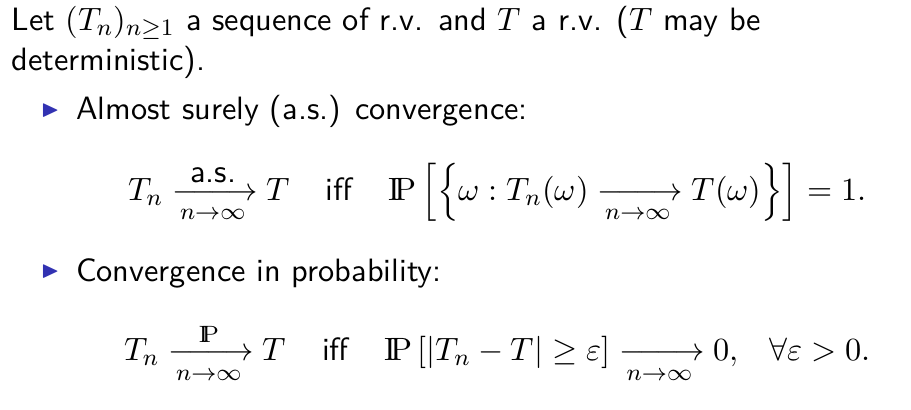
- (收敛和分布收敛)

- 分布收敛的等价表述

- 几种收敛的强弱比较(a.s:几乎必然收敛almost surely convergence)


- 另一个例子
- delta 方法

- Slutsky’s theorem

- delta 方法
problemset1
- 马尔可夫不等式

- problem1



- 凑中心极限定理那个分布
Parametric Inference
样本数的限制:需要假设以限制模型在一个看似合理的子空间

- statistic models


- 有限参数即可描述的模型:参数化模型
- 样本空间的取值范围中不能含有要估计的参数(均匀分布,在实验之前应该是所有可能的值)
- identification
injective:单射

- parameter estimation


- confidence interval


- strongly consistent:强一致性(as收敛),弱一致就是概率收敛
problemset2
- consistent estimater(一致估计量):就是按那4种收敛过去
- 对n重伯努利的p(1-p)的无偏估计:
- 直接用,估算出来有偏差所以将其缩放为n/n-1倍
- quantile:就是标准正态分布下概率为多少的值(0.95的约为1.96,意思就是负无穷到1.96的概率累积函数值为.95)

Maximum Likelihood Estimation
total variation distance


- 一些性质(类似线代里面的广义向量、满足这些就算距离)
- 连续的就是差的绝对值积分
- A是全集的一个子集!!!

- 一种利用该距离搜索最优参数的方法,建立估计器并最小化(老问题,真实参数不知道算不了)
KL divergence


- 由KL散度建立的估计器

- definiteness so the minimizer is unique from p to KL
- identities so unique from to KL
- 期望的分布(概率)仅仅决定了采样方式,与被采样的数据无关

- intuition:就是在得到一些观测值之后最大化这些观测值在曲线(密度)上的概率值
- concave:凹函数(二阶导小于零)
- 多维情况:
- likelihood

- 连续就是PMF换PDF
最大似然估计器

- 费雪信息
- 实际上实在反映我的曲线的陡峭程度(曲线越陡,最小化KL散度计算出的参数估计值和真实值之间越接近how robust my estimator be)


- 一些假设

The method of Moment
斯通-魏尔斯特拉斯定理

- weierstrass approximation


- 仅对连续变量有用,要求研究范围有界,并且不知道d要算到多少阶
- Gaussian quadrature(高斯积分)
- 当随机变量离散的时候:由于概率和为1,我们仅需要至多r-1个参数即可描述分布

- x矩阵是个范德蒙行列式,肯定有唯一解
- 当随机变量离散的时候:由于概率和为1,我们仅需要至多r-1个参数即可描述分布
method of moment
- tip:矩阵的condition number(条件数)用于衡量对输入波动的敏感性
- 矩阵的诱导范数(induced norm):
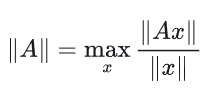
- 条件数为

- 矩阵的诱导范数(induced norm):
- 矩方法估计器就是该函数的取逆(所以该可逆函数的性质非常重要)
- 对该估计器的分析:


- 对该估计器的分析:
- 两者的比较:从风险上看MLE更优,但是MLE的优化通常比较困难,尤其在目标函数非凹时。
problemset3
- 连续变量的似然估计就是直接密度函数
- 最大似然估计的时候不一定有导数零点
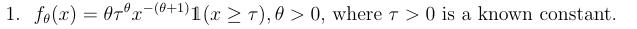
- 双线表示指示函数,满足条件为1
- 算KL散度:先别急着化成期望(两个期望不一定好算)
- dirac distribution
- in distribution concept:it takes 1 in the only point of support set
problemset4
- !!!正态分布的第二个参数是所以费雪矩阵是对平方求导
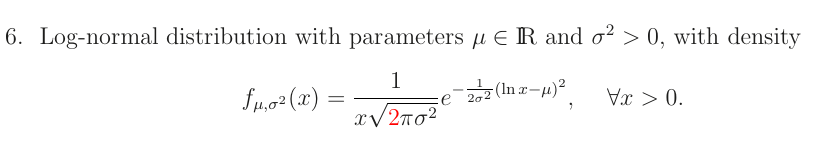
- 对数正态分布:令y=lnx,则有服从一般正态分布
- 矩估计:样本矩等于理论矩

- 这里有个矩生成函数
Parametric hypothesis testing

- 我们只关心均值,所以我们可以做出方差和分布类型均不变的假设
- 直接中心极限定理的缺点:均值是渐进意义上的接近,如果样本量小,有波动
- 更好的方法是留下一个buffer(这个buffer在n接近无穷的时候接近0)在x和103.5之间
- placbo(安慰剂)
- Heuristics(启发式)
- status quo:现状




- test statistic:检验统计量(statistic:measurable function depend on data)
example:

- 实际上算T的时候应该是所有在0区间的参数的值,因为该例子中的区间中的值只有一个所以直接算的0.5
- 存在一个level为反转点(大于这个level我就reject)
- 根据我的数据来假设使p value偏大实际上违背了统计原则

some weird distribution


- 这实际上是在使用中心极限定理(我们通常使用经验方差代替真实方差)的时候直接带真实方差(实际上可能有一个细微的差别,因为样本方差实际服从的是n-1的卡方分布)
- e.g:

- 计算实际参数和真实参数是否接近:直接算欧几里得范数

- 信息几何:在费雪矩阵定义的空间(可能是一些很奇怪的弯曲的空间)上加权求距离
- e.g:likihood ratio test
null hypothesis:假设一部分参数为固定值
有两个最大似然估计的估计器:仅考虑null假设、考虑全体,后者估计器的数值必定大于等于前者

test implicit hypothesis

- 随机变量服从K维标准正态分布,则其二次型服从K个自由度的卡方分布
- 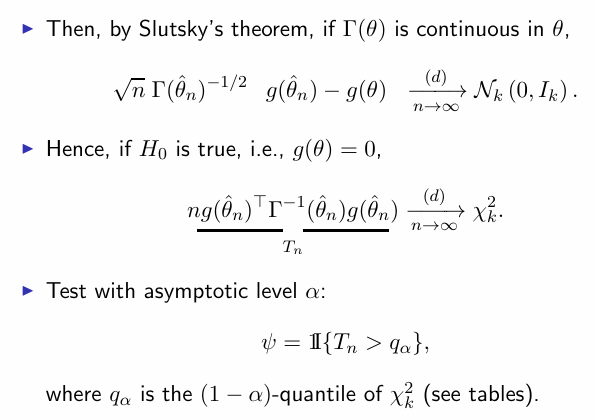
-
卡方检验


- test:是否参数向量为某个参数向量(e.g:测试是否某个分布为均匀分布)
-
t 检验


- 非渐进、并且可以运行在小样本上
- 但是要求你假设你的数据本身是正态分布的
testing goodness of fit
- 我们想要知道假设的分布是否能够很好地近似拟合数据
经验累计函数

- 这实际上强于大数定理:可能n是一个依赖于其它参数的函数


- 实际上B指布朗桥(当检验正态性时不能直接插入经验均值和方差)

- 检验:是否服从正态分布:
- 然后可以换元将前一项变为
- 可以同除变换证明左边不依赖我的统计数据
 (直接查表,数值模拟)
(直接查表,数值模拟)- 这就是KLtest:数据是否服从某未知参数的正态分布(KS是已知)
- KS test



- reordered:实际给你的数据不一定是按照大小排好的,我们重新排过
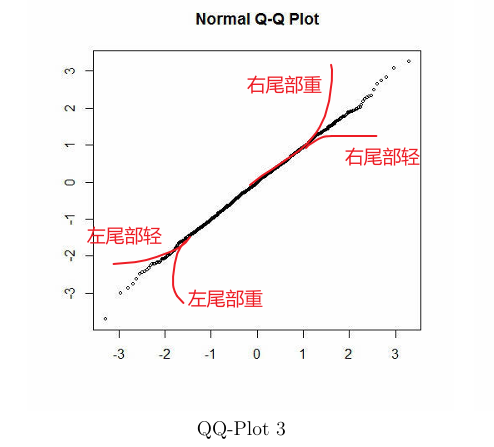
- (QQ plot)检验一分布是否符合高斯:实际上主要是看它的尾部而不是均值附近

- 可以判别左尾部和右尾部与高斯相比哪个更重(分位数映射回密度函数再比较)
- 卡方拟合优度检验
- 要不本身离散,要不分箱离散化分布
- (参数维度越大,越难以逃离空间,自由度越小)

problemset6
- 区分:单边检验和双边检验(前者绝对值小于某个阈值)
- 检验要得到的是关于估计量的分布!!!
- 构造检验:
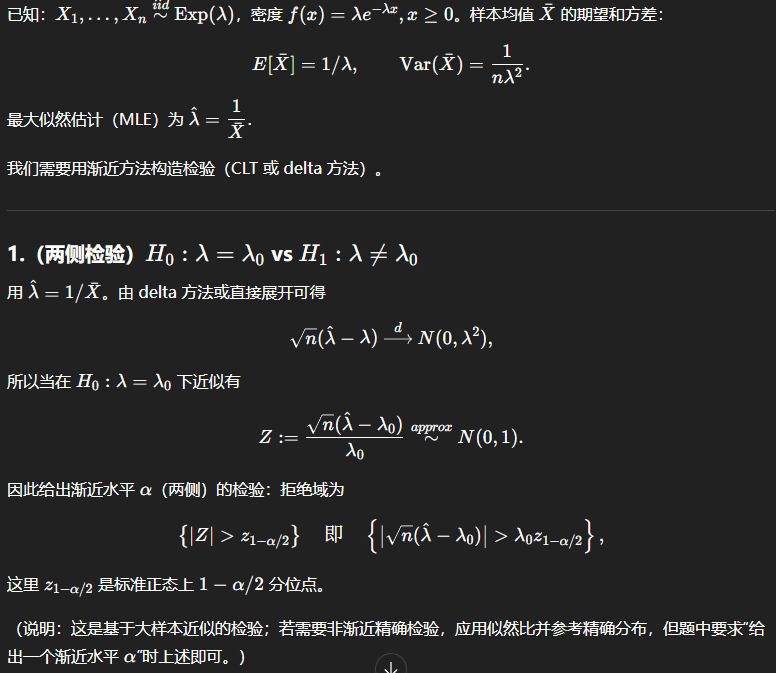

- 看清楚:到底算的是统计量的方差还是理论值
regression
linear(single)

- trick:先带进去更好算(也不好说( )
- 若设(当最小化时)
- 则有

linear(multivariate)
- intercept:截距


- homoscedasticity:同方差性(误差项的方差在所有的观察值中保持不变)
- 实际上可以理解为我的观测值从真正的超平面中偏离的向量值


- 直接将中的y带入真实值,可以得到估计值与真实值之间相差一个均值为0的高斯分布
- 当误差不是独立同分布的高斯时,MLE可能会产生某些奇怪的估计器
- 预测误差:这里复习一下线代
significance test
- claim:对向量 ej就是仅在j位置为1的向量

这种方法同时检验多个不太好
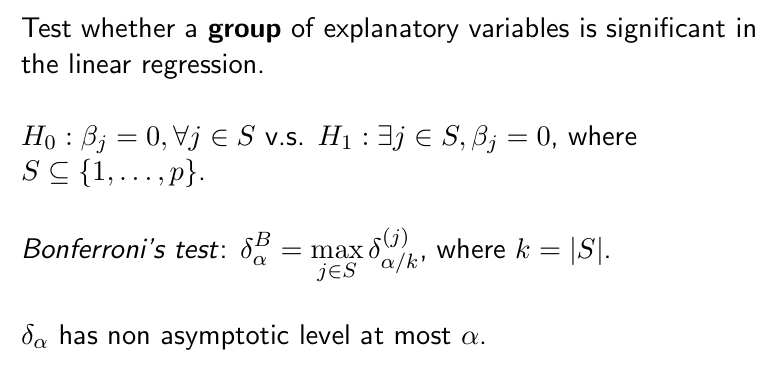
more test

-
claim:
-
线性回归只能展现相关性,不能说明因果关系

-
上述均建立在我们的X矩阵为方阵(样本数和特征数相同)的前提下,此时我们可以求x与其转置乘积的逆
-
当x的秩不是p的时候:我们的估计不唯一

- 矩阵广义逆
high dimension
当p过大的时候:降维(假设只有一部分的系数非零)

- AIC(赤池信息准则):倾向于准确度高的
- BIC:倾向于简单的
上述找的是相当于矩阵的0阶范数作罚项(计算困难,非凸)
solution:换成一阶范数(lasso estimator)
nonparametric regression
- 回归的时候,常规的做法都是对其参数进行了一定的假设
- idea(假设函数f是光滑的,f可以被分段常值函数很好地近似)
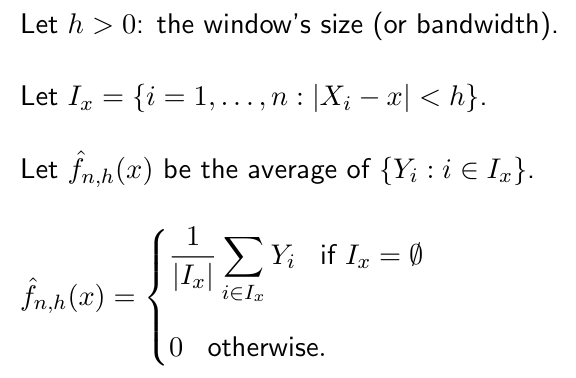
- h接近于0时过拟合,无穷时欠拟合
- 选h:如果曲率知道,根据这个来选,不知道就得cross validation了
problemset7
- qq plot 实际上可以检验很多,常见为正态分布
- pivitol statistic:不依赖未知参数的统计量
- 一串独立同分布的随机变量X序列,按大小来排,各序列的概率是相等的,所以其rank变量序列与X无关
- 所以独立变量对(R,Q)和独立变量对(R`,Q`)均独立同分布(后者为任意分布中取的n个变量的分位数)
- 独立变量的函数也是独立的
bayesian statistics
- 先验belief->后验belief(通过数据
- e.g:想测试某地的人口性别比是不是1:1
- 假设我们有90%的把握女性在0.4~0.6之间,我们可以把p建模为一个随机变量(虽然实际上的比例p不是随机变量,这只是建模方法)
- 常见(0,1)上的分布

- 如果后验和先验是一样的分布,这叫共轭先验(conjugate prior)
bayesian rules

- 理解:实际上后验分布只是缩放了我根据先验加权过的似然

non informative prior


- 实际上虽然我只是给出了参数在0~1的范围,实际上蕴含着它不太可能是0或1(所以最后的分布参数有个+1)


- 重参数化不变原则

bayesian estimate

- 贝叶斯适合小样本,并且理论上能说参数落在这里面的概率是



problemset 8
- 矩阵范数:自身转置乘自身求迹
- 想清楚你求导的是矩阵还是向量
线代复习:linear algebra


