defpad_sents(sents, pad_token): """ Pad list of sentences according to the longest sentence in the batch. The paddings should be at the end of each sentence. @param sents (list[list[str]]): list of sentences, where each sentence is represented as a list of words @param pad_token (str): padding token @returns sents_padded (list[list[str]]): list of sentences where sentences shorter than the max length sentence are padded out with the pad_token, such that each sentences in the batch now has equal length. """ sents_padded = []
### YOUR CODE HERE (~6 Lines) max_length=-1 for sentense in sents: max_length=len(sentense) if max_length<len(sentense) else max_length for sentense in sents: sents_padded.append(sentense+(max_length-len(sentense)*[pad_token])#注意一个句子是list[str]类型,添加的填充词汇应该是以重复列表的形式加进去 ### END YOUR CODE
return sents_padded
func2:
defencode(self, source_padded: torch.Tensor, source_lengths: List[int], grader_params=None) -> Tuple[ torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]: """ Apply the encoder to source sentences to obtain encoder hidden states. Additionally, take the final states of the encoder and project them to obtain initial states for decoder. @param source_padded (Tensor): Tensor of padded source sentences with shape (src_len, b), where b = batch_size, src_len = maximum source sentence length. Note that these have already been sorted in order of longest to shortest sentence. @param source_lengths (List[int]): List of actual lengths for each of the source sentences in the batch @returns enc_hiddens (Tensor): Tensor of hidden units with shape (b, src_len, h*2), where b = batch size, src_len = maximum source sentence length, h = hidden size. @returns dec_init_state (tuple(Tensor, Tensor): Tuple of tensors representing the decoder's initial hidden state and cell. @grader_params: Ignore this parameter. It is used for grading purposes. """ enc_hiddens, dec_init_state = None, None
### YOUR CODE HERE (~ 11 Lines) X=self.model_embeddings.source(source_padded)#应该直接调用其source方法而不是直接将整个类作为函数调用,否则会触发默认调用forward方法 x=torch.permute(self.post_embed_cnn(torch.permute(X,(1,2,0)),(2,0,1) x_i =nn.utils.rnn.pack_padded_sequence(x,lengths=source_lengths,batch_first=False)#!打包序列 (注意batch_first=False因为输入是src_len第一维) enc,(last_hidden,last_cell)=self.encoder(x_i)#对双向网络而言,其返回隐状态包含了正向和反向 enc_h,_=nn.utils.rnn.pad_packed_sequence(enc,batch_first=False) enc_hiddens=torch.permute(enc_h,(1,0,2) init_decoder_hidden=self.h_projection(torch.cat((last_hidden[0],last_hidden[1]),dim=1)#正确处理,正反向正确拼接 init_decoder_cell=self.c_projection(torch.cat((last_cell[0],last_cell[1]),dim=1) dec_init_state=(init_decoder_hidden,init_decoder_cell)#解码器需要的就是元组 ### TODO: ### 1. Construct Tensor `X` of source sentences with shape (src_len, b, e) using the source model embeddings. ### src_len = maximum source sentence length, b = batch size, e = embedding size. Note ### that there is no initial hidden state or cell for the encoder. ### 2. Apply the post_embed_cnn layer. Before feeding X into the CNN, first use torch.permute to change the ### shape of X to (b, e, src_len). After getting the output from the CNN, remember to use torch.permute ### again to revert X back to its original shape. ### 3. Compute `enc_hiddens`, `last_hidden`, `last_cell` by applying the encoder to `X`. ### - Before you can apply the encoder, you need to apply the `pack_padded_sequence` function to X. ### - After you apply the encoder, you need to apply the `pad_packed_sequence` function to enc_hiddens. ### - Note that the shape of the tensor returned by the encoder is (src_len, b, h*2) and we want to ### return a tensor of shape (b, src_len, h*2) as `enc_hiddens`. ### 4. Compute `dec_init_state` = (init_decoder_hidden, init_decoder_cell): ### - `init_decoder_hidden`: ### `last_hidden` is a tensor shape (2, b, h). The first dimension corresponds to forwards and backwards. ### Concatenate the forwards and backwards tensors to obtain a tensor shape (b, 2*h). ### Apply the h_projection layer to this in order to compute init_decoder_hidden. ### This is h_0^{dec} in the PDF. Here b = batch size, h = hidden size ### - `init_decoder_cell`: ### `last_cell` is a tensor shape (2, b, h). The first dimension corresponds to forwards and backwards. ### Concatenate the forwards and backwards tensors to obtain a tensor shape (b, 2*h). ### Apply the c_projection layer to this in order to compute init_decoder_cell. ### This is c_0^{dec} in the PDF. Here b = batch size, h = hidden size ### ### See the following docs, as you may need to use some of the following functions in your implementation: ### Pack the padded sequence X before passing to the encoder: ### https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pack_padded_sequence.html ### Pad the packed sequence, enc_hiddens, returned by the encoder: ### https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_packed_sequence.html ### Tensor Concatenation: ### https://pytorch.org/docs/stable/generated/torch.cat.html ### Tensor Permute: ### https://pytorch.org/docs/stable/generated/torch.permute.html
### END YOUR CODE
return enc_hiddens, dec_init_state
func3
def__init__(self, embed_size, hidden_size, vocab, dropout_rate=0.2): """ Init NMT Model. @param embed_size (int): Embedding size (dimensionality) @param hidden_size (int): Hidden Size, the size of hidden states (dimensionality) @param vocab (Vocab): Vocabulary object containing src and tgt languages See vocab.py for documentation. @param dropout_rate (float): Dropout probability, for attention """ super(NMT, self).__init__() self.model_embeddings = ModelEmbeddings(embed_size, vocab) self.hidden_size = hidden_size self.dropout_rate = dropout_rate self.vocab = vocab
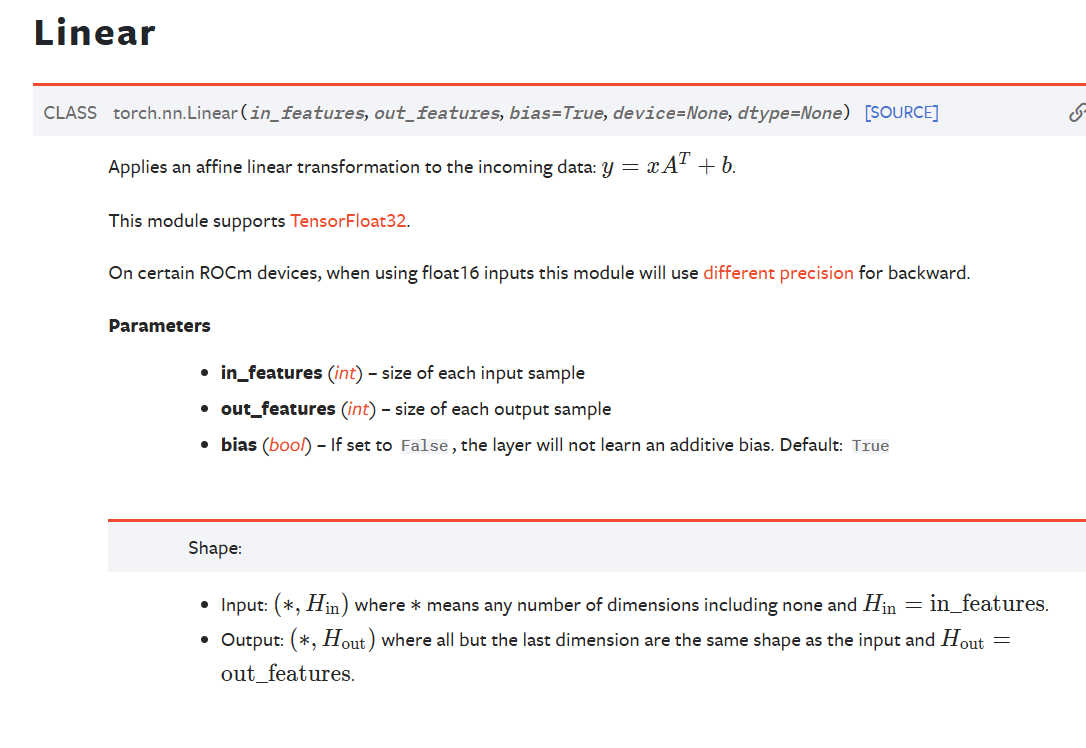
### YOUR CODE HERE (~9 Lines) self.post_embed_cnn=nn.Conv1d(embed_size,embed_size,kernel_size=2,padding="same") #卷积层!不是设定input和output就完事!!!动态填充,确保一定能够是完全相同的形状 #看看计算对不对 self.encoder=nn.LSTM(embed_size,self.hidden_size,bidirectional=True) self.decoder=nn.LSTMCell(embed_size+self.hidden_size,self.hidden_size,bias=True) self.h_projection=nn.Linear(2*self.hidden_size,self.hidden_size,bias=False)#2在前面 self.c_projection=nn.Linear(2*self.hidden_size,self.hidden_size,bias=False) self.att_projection=nn.Linear(2*self.hidden_size,self.hidden_size,bias=False) self.combined_output_projection=nn.Linear(3*self.hidden_size,self.hidden_size,bias=False) self.target_vocab_projection=nn.Linear(self.hidden_size,len(self.vocab.tgt),bias=False)#从隐藏映射出去 self.dropout=nn.Dropout(self.dropout_rate) ### TODO - Initialize the following variables IN THIS ORDER: ### self.post_embed_cnn (Conv1d layer with kernel size 2, input and output channels = embed_size, ### padding = same to preserve output shape ) ### self.encoder (Bidirectional LSTM with bias) ### self.decoder (LSTM Cell with bias) ### self.h_projection (Linear Layer with no bias), called W_{h} in the PDF. ### self.c_projection (Linear Layer with no bias), called W_{c} in the PDF. ### self.att_projection (Linear Layer with no bias), called W_{attProj} in the PDF. ### self.combined_output_projection (Linear Layer with no bias), called W_{u} in the PDF. ### self.target_vocab_projection (Linear Layer with no bias), called W_{vocab} in the PDF. ### self.dropout (Dropout Layer) ### ### Use the following docs to properly initialize these variables: ### Conv1d: ### https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html ### LSTM: ### https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html ### LSTM Cell: ### https://pytorch.org/docs/stable/generated/torch.nn.LSTMCell.html ### Linear Layer: ### https://pytorch.org/docs/stable/generated/torch.nn.Linear.html ### Dropout Layer: ### https://pytorch.org/docs/stable/generated/torch.nn.Dropout.html
### END YOUR CODE
func4
defdecode(self, enc_hiddens: torch.Tensor, enc_masks: torch.Tensor, dec_init_state: Tuple[torch.Tensor, torch.Tensor], target_padded: torch.Tensor) -> torch.Tensor: """Compute combined output vectors for a batch. @param enc_hiddens (Tensor): Hidden states (b, src_len, h*2), where b = batch size, src_len = maximum source sentence length, h = hidden size. @param enc_masks (Tensor): Tensor of sentence masks (b, src_len), where b = batch size, src_len = maximum source sentence length. @param dec_init_state (tuple(Tensor, Tensor): Initial state and cell for decoder @param target_padded (Tensor): Gold-standard padded target sentences (tgt_len, b), where tgt_len = maximum target sentence length, b = batch size. @returns combined_outputs (Tensor): combined output tensor (tgt_len, b, h), where tgt_len = maximum target sentence length, b = batch_size, h = hidden size """ # Chop off the <END> token for max length sentences. target_padded = target_padded[:-1]
# Initialize the decoder state (hidden and cell) dec_state = dec_init_state
# Initialize previous combined output vector o_{t-1} as zero batch_size = enc_hiddens.size(0) o_prev = torch.zeros(batch_size, self.hidden_size, device=self.device)
# Initialize a list we will use to collect the combined output o_t on each step combined_outputs = []
### YOUR CODE HERE (~9 Lines) enc_hiddens_proj=self.att_projection(enc_hiddens) Y=self.model_embeddings.target(target_padded) for Y_t in torch.split(Y,1):#默认从dim=0切 Y_t=torch.squeeze(Y_t)#默认把长度为1的去掉了 Ybar_t=torch.cat((Y_t,o_prev),dim=-1) dec_state,output,e_t=self.step(Ybar_t, dec_state, enc_hiddens, enc_hiddens_proj, enc_masks) combined_outputs.append(output) o_prev=output combined_outputs=torch.stack(combined_outputs,dim=0) ### TODO: ### 1. Apply the attention projection layer to `enc_hiddens` to obtain `enc_hiddens_proj`, ### which should be shape (b, src_len, h), ### where b = batch size, src_len = maximum source length, h = hidden size. ### This is applying W_{attProj} to h^enc, as described in the PDF. ### 2. Construct tensor `Y` of target sentences with shape (tgt_len, b, e) using the target model embeddings. ### where tgt_len = maximum target sentence length, b = batch size, e = embedding size. ### 3. Use the torch.split function to iterate over the time dimension of Y. ### Within the loop, this will give you Y_t of shape (1, b, e) where b = batch size, e = embedding size. ### - Squeeze Y_t into a tensor of dimension (b, e). ### - Construct Ybar_t by concatenating Y_t with o_prev on their last dimension ### - Use the step function to compute the the Decoder's next (cell, state) values ### as well as the new combined output o_t. ### - Append o_t to combined_outputs ### - Update o_prev to the new o_t. ### 4. Use torch.stack to convert combined_outputs from a list length tgt_len of ### tensors shape (b, h), to a single tensor shape (tgt_len, b, h) ### where tgt_len = maximum target sentence length, b = batch size, h = hidden size. ### ### Note: ### - When using the squeeze() function make sure to specify the dimension you want to squeeze ### over. Otherwise, you will remove the batch dimension accidentally, if batch_size = 1. ### ### You may find some of these functions useful: ### Zeros Tensor: ### https://pytorch.org/docs/stable/generated/torch.zeros.html ### Tensor Splitting (iteration): ### https://pytorch.org/docs/stable/generated/torch.split.html ### Tensor Dimension Squeezing: ### https://pytorch.org/docs/stable/generated/torch.squeeze.html ### Tensor Concatenation: ### https://pytorch.org/docs/stable/generated/torch.cat.html ### Tensor Stacking: ### https://pytorch.org/docs/stable/generated/torch.stack.html
### END YOUR CODE
return combined_outputs
func5
defstep(self, Ybar_t: torch.Tensor, dec_state: Tuple[torch.Tensor, torch.Tensor], enc_hiddens: torch.Tensor, enc_hiddens_proj: torch.Tensor, enc_masks: torch.Tensor) -> Tuple[Tuple, torch.Tensor, torch.Tensor]: """ Compute one forward step of the LSTM decoder, including the attention computation. @param Ybar_t (Tensor): Concatenated Tensor of [Y_t o_prev], with shape (b, e + h). The input for the decoder, where b = batch size, e = embedding size, h = hidden size. @param dec_state (tuple(Tensor, Tensor): Tuple of tensors both with shape (b, h), where b = batch size, h = hidden size. First tensor is decoder's prev hidden state, second tensor is decoder's prev cell. @param enc_hiddens (Tensor): Encoder hidden states Tensor, with shape (b, src_len, h * 2), where b = batch size, src_len = maximum source length, h = hidden size. @param enc_hiddens_proj (Tensor): Encoder hidden states Tensor, projected from (h * 2) to h. Tensor is with shape (b, src_len, h), where b = batch size, src_len = maximum source length, h = hidden size. @param enc_masks (Tensor): Tensor of sentence masks shape (b, src_len), where b = batch size, src_len is maximum source length. @returns dec_state (tuple (Tensor, Tensor): Tuple of tensors both shape (b, h), where b = batch size, h = hidden size. First tensor is decoder's new hidden state, second tensor is decoder's new cell. @returns combined_output (Tensor): Combined output Tensor at timestep t, shape (b, h), where b = batch size, h = hidden size. @returns e_t (Tensor): Tensor of shape (b, src_len). It is attention scores distribution. Note: You will not use this outside of this function. We are simply returning this value so that we can sanity check your implementation. """
combined_output = None
### YOUR CODE HERE (~3 Lines) dec_state=self.decoder(Ybar_t,dec_state) dec_hidden,dec_cell=dec_state[0],dec_state[1] e_t=torch.squeeze(torch.bmm(torch.unsqueeze(dec_hidden,dim=1),torch.permute(enc_hiddens_proj,(0,2,1)),dim=1) #squeeze还是指定维度更好 #理解:enc_hiddens_proj是投影过后的hidden ### TODO: ### 1. Apply the decoder to `Ybar_t` and `dec_state`to obtain the new dec_state. ### 2. Split dec_state into its two parts (dec_hidden, dec_cell) ### 3. Compute the attention scores e_t, a Tensor shape (b, src_len). ### Note: b = batch_size, src_len = maximum source length, h = hidden size. ### ### Hints: ### - dec_hidden is shape (b, h) and corresponds to h^dec_t in the PDF (batched) ### - enc_hiddens_proj is shape (b, src_len, h) and corresponds to W_{attProj} h^enc (batched). ### - Use batched matrix multiplication (torch.bmm) to compute e_t (be careful about the input/ output shapes!) ### - To get the tensors into the right shapes for bmm, you will need to do some squeezing and unsqueezing. ### - When using the squeeze() function make sure to specify the dimension you want to squeeze ### over. Otherwise, you will remove the batch dimension accidentally, if batch_size = 1. ### ### Use the following docs to implement this functionality: ### Batch Multiplication: ### https://pytorch.org/docs/stable/generated/torch.bmm.html ### Tensor Unsqueeze: ### https://pytorch.org/docs/stable/generated/torch.unsqueeze.html ### Tensor Squeeze: ### https://pytorch.org/docs/stable/generated/torch.squeeze.html
### END YOUR CODE
# Set e_t to -inf where enc_masks has 1 if enc_masks isnotNone: e_t.data.masked_fill_(enc_masks.bool(), -float('inf')
### YOUR CODE HERE (~6 Lines) alpha_t=F.softmax(e_t,dim=1) a_t=torch.squeeze(torch.bmm(torch.unsqueeze(alpha_t,dim=1),enc_hiddens),dim=1) U_t=torch.cat((dec_hidden,a_t),dim=1) #torch.cat:dim设置的哪个,哪个dim的值就变大(简记) V_t=self.combined_output_projection(U_t) O_t=self.dropout(torch.tanh(V_t) ### TODO: ### 1. Apply softmax to e_t to yield alpha_t ### 2. Use batched matrix multiplication between alpha_t and enc_hiddens to obtain the ### attention output vector, a_t. ### - alpha_t is shape (b, src_len) ### - enc_hiddens is shape (b, src_len, 2h) ### - a_t should be shape (b, 2h) ### - You will need to do some squeezing and unsqueezing. ### Note: b = batch size, src_len = maximum source length, h = hidden size. ### ### 3. Concatenate dec_hidden with a_t to compute tensor U_t ### 4. Apply the combined output projection layer to U_t to compute tensor V_t ### 5. Compute tensor O_t by first applying the Tanh function and then the dropout layer. ### ### Use the following docs to implement this functionality: ### Softmax: ### https://pytorch.org/docs/stable/generated/torch.nn.functional.softmax.html ### Batch Multiplication: ### https://pytorch.org/docs/stable/generated/torch.bmm.html ### Tensor View: ### https://pytorch.org/docs/stable/generated/torch.Tensor.view.html ### Tensor Concatenation: ### https://pytorch.org/docs/stable/generated/torch.cat.html ### Tanh: ### https://pytorch.org/docs/stable/generated/torch.tanh.html