
week4
project

lecture 8:transformer
自注意力
- attention 可以将其视作对键-值存贮执行模糊查找
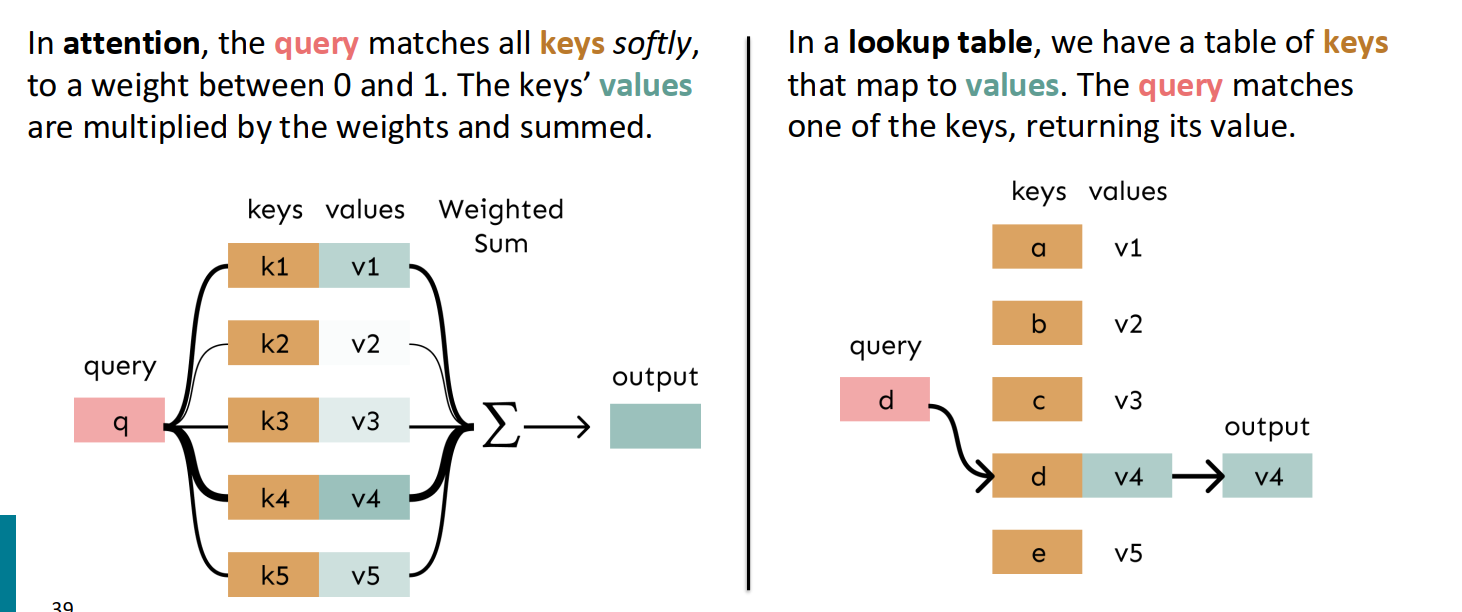
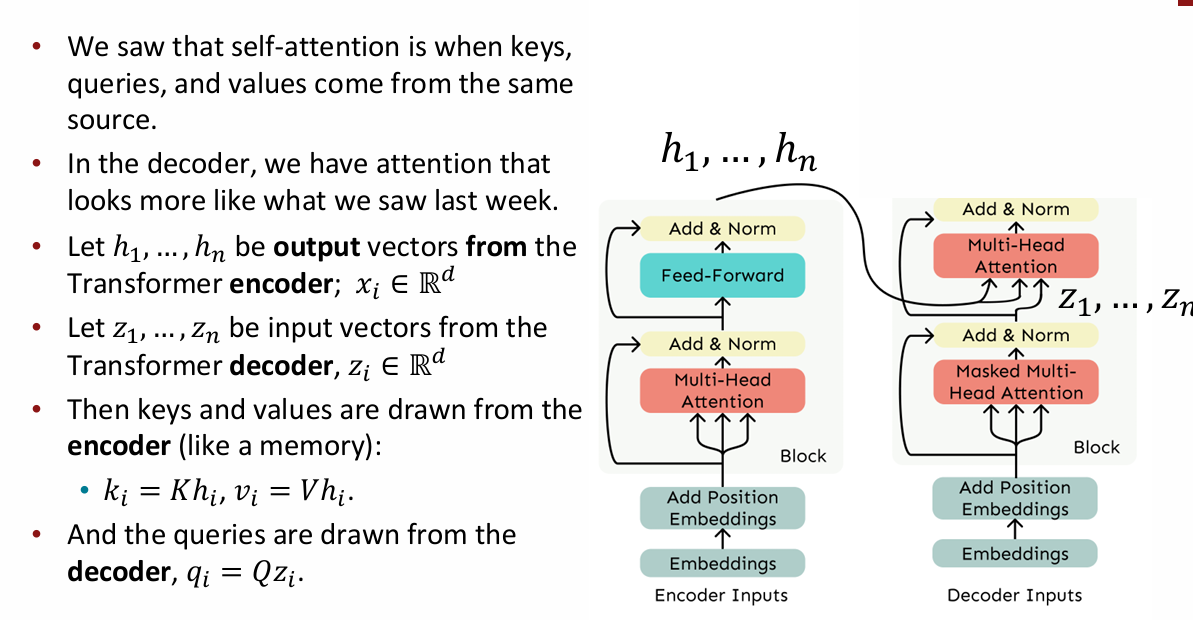
- 之前的cross attention:对x投入注意力来生成输出序列(y)
- self attention对y投入注意力来输出y

单纯自注意力的问题
没有对序列位置信息的编码
solution:
编码位置向量序列变化为
如何得到位置向量(传统方法):
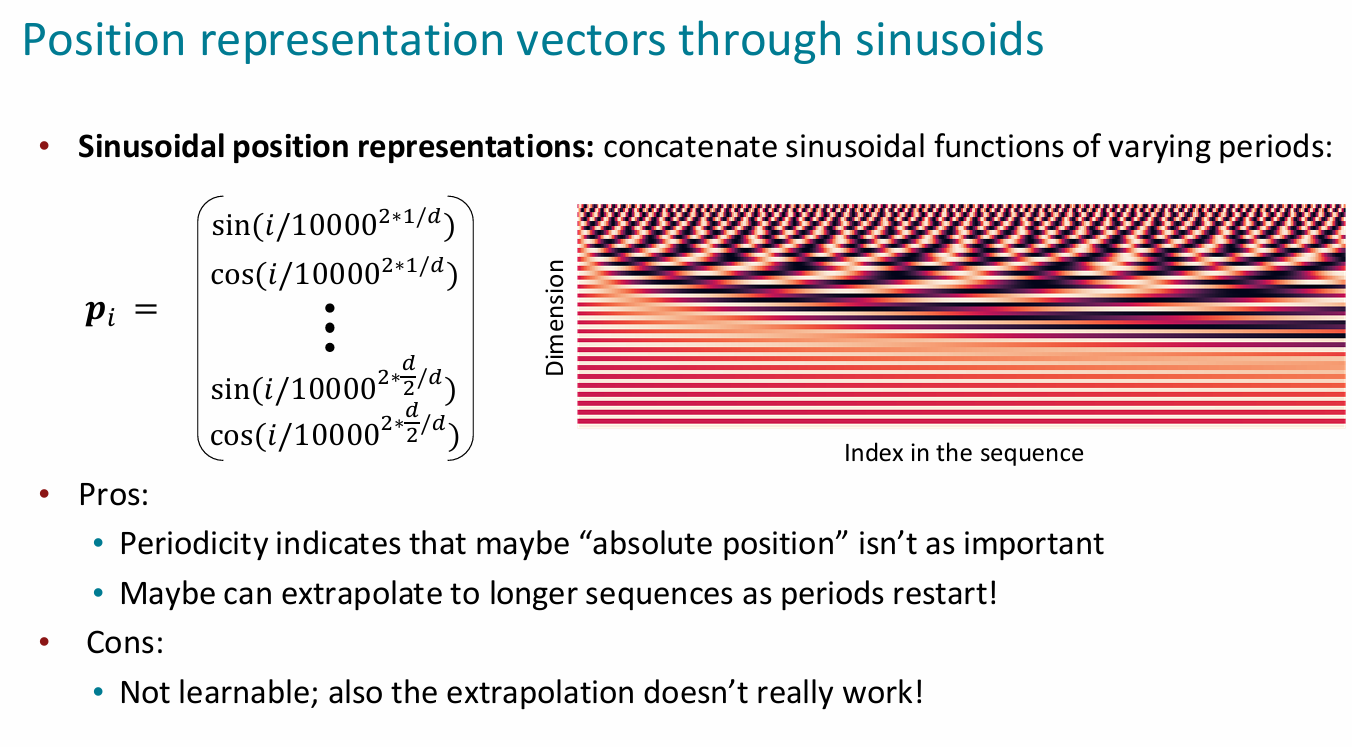
神经方法:

为什么知道学习的是位置:因为其只随着位置索引的不同在改变(而你输入的词嵌入是会改变的)
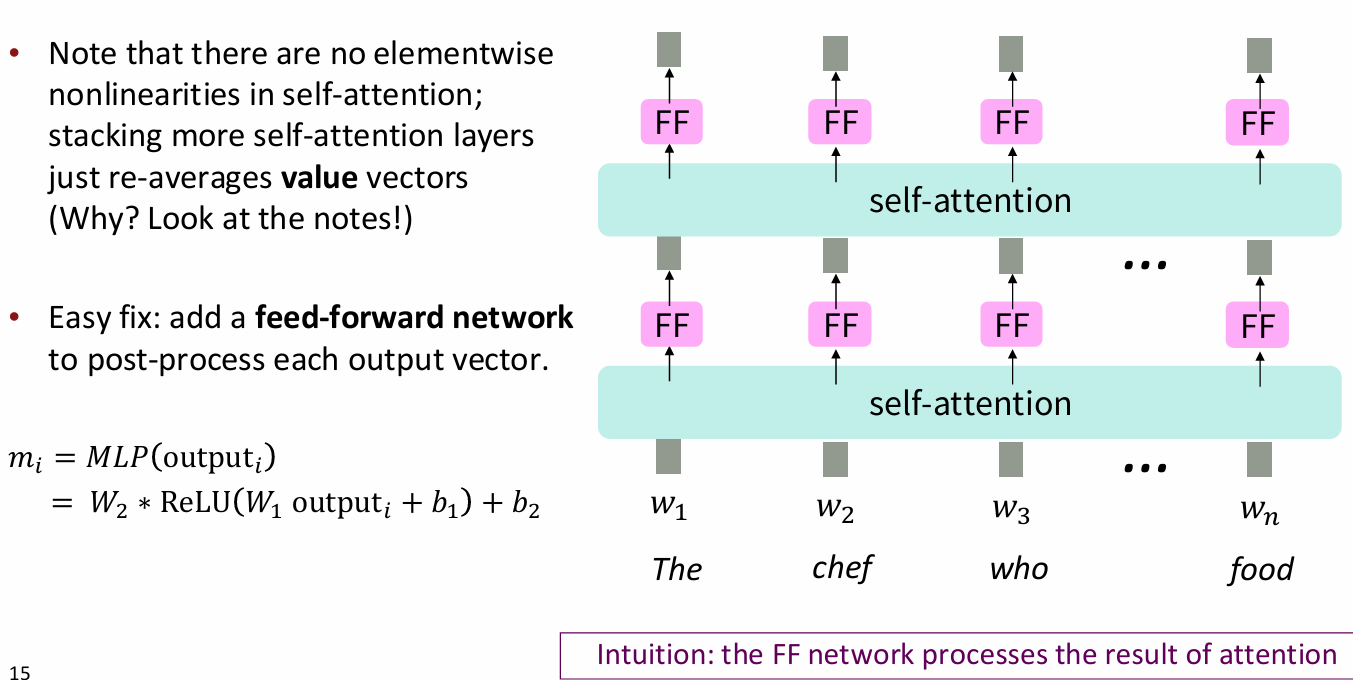
没有传统的非线性处理
solution:在注意力处理中加入多层感知机
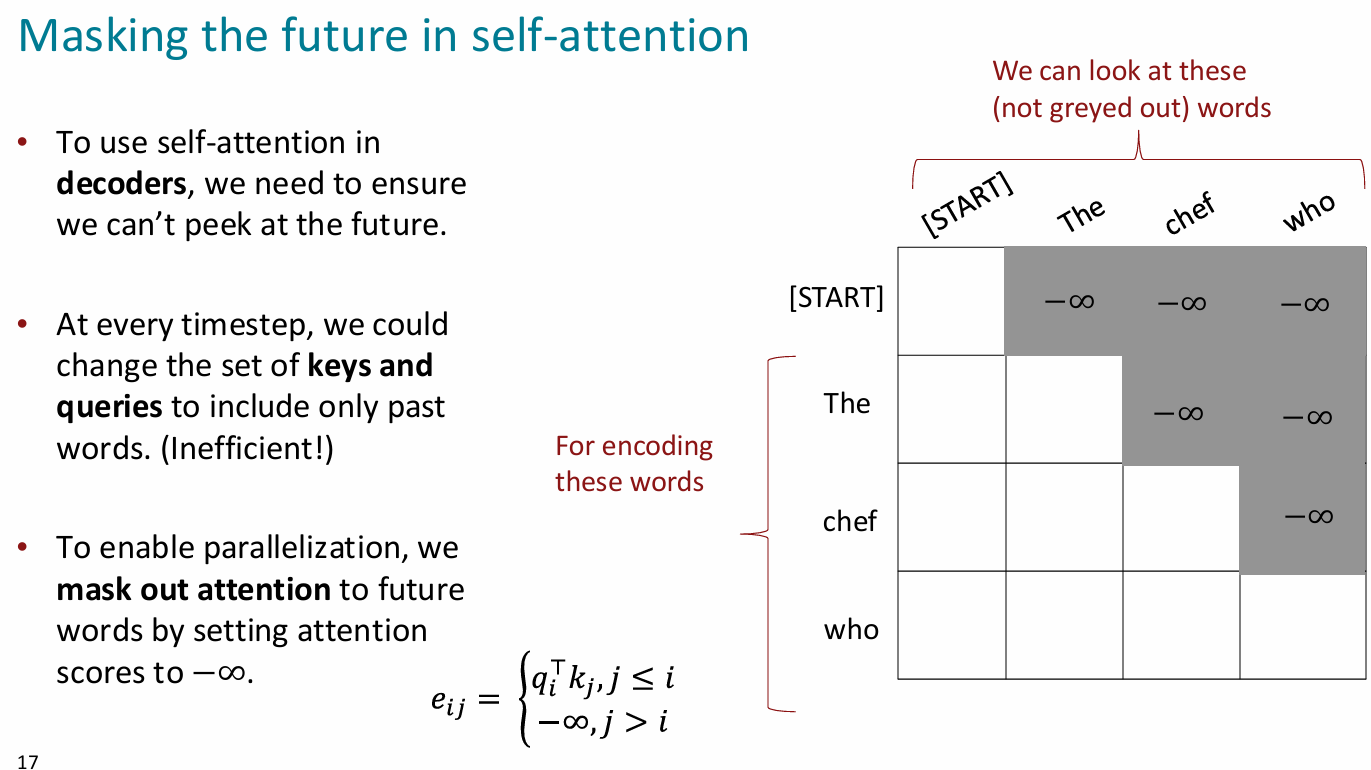
预测序列时没有未来的输入(使用受限)
solution:对自注意力使用掩码
传统上用于decoder而不是encoder
e.g机器翻译中,在原句子encode的过程中不使用,而在翻译进行到某一步的时候将之后的目标语句掩码
最小的自注意力块

transformer
多头注意力

- 实际上并没有添加额外的计算开销,只是单纯的分开
- 不同的块之间通常参数不共享
- 通常头的数量是一样多的(基于给定的模型维度大概有多少个头的效果比较好)
- 目前还没有关于把头的数量弄的不一样的直觉和做法
缩放点积注意力
- 实际上就是个小trick

另外两个小技巧
- 残差链接:resnet
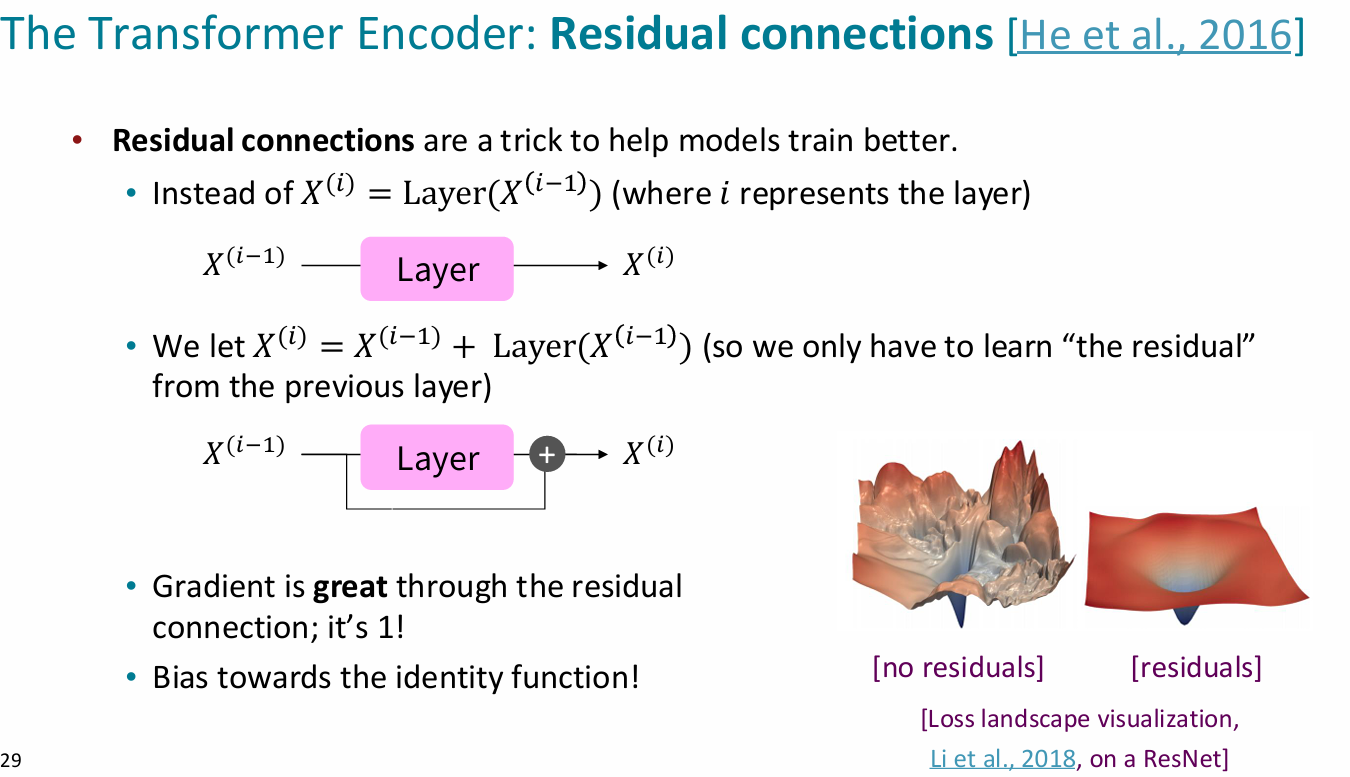
- 层标准化(layer normalization)

transformer架构完全体
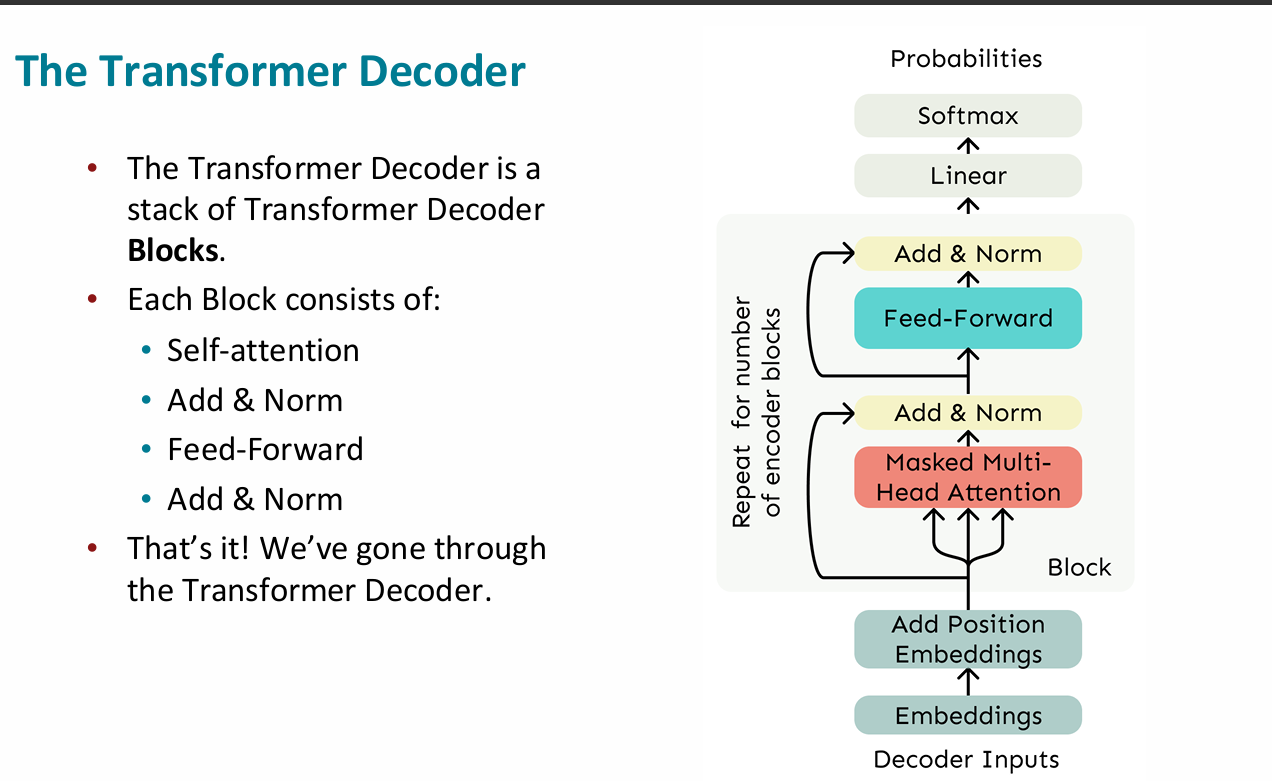
- decoder
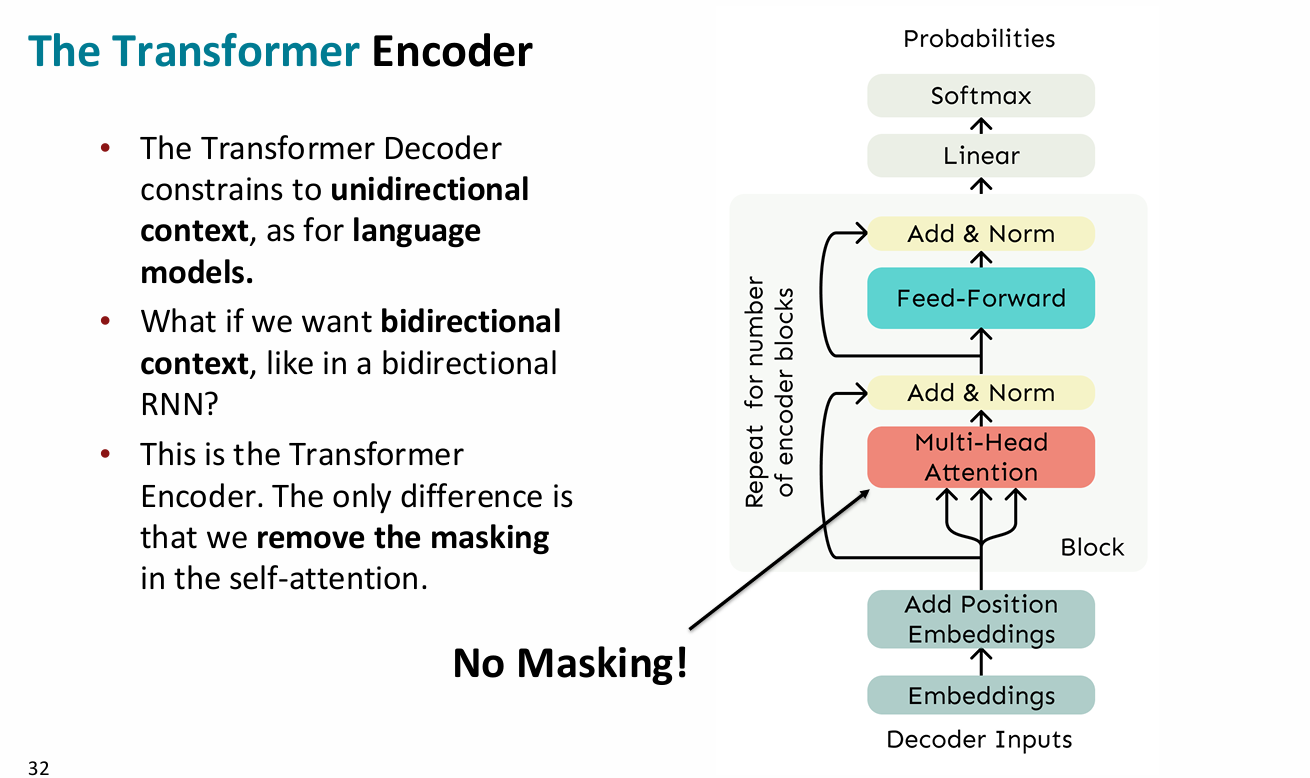
通常那个前馈神经网络只有一个隐藏层 - encoder
e-d
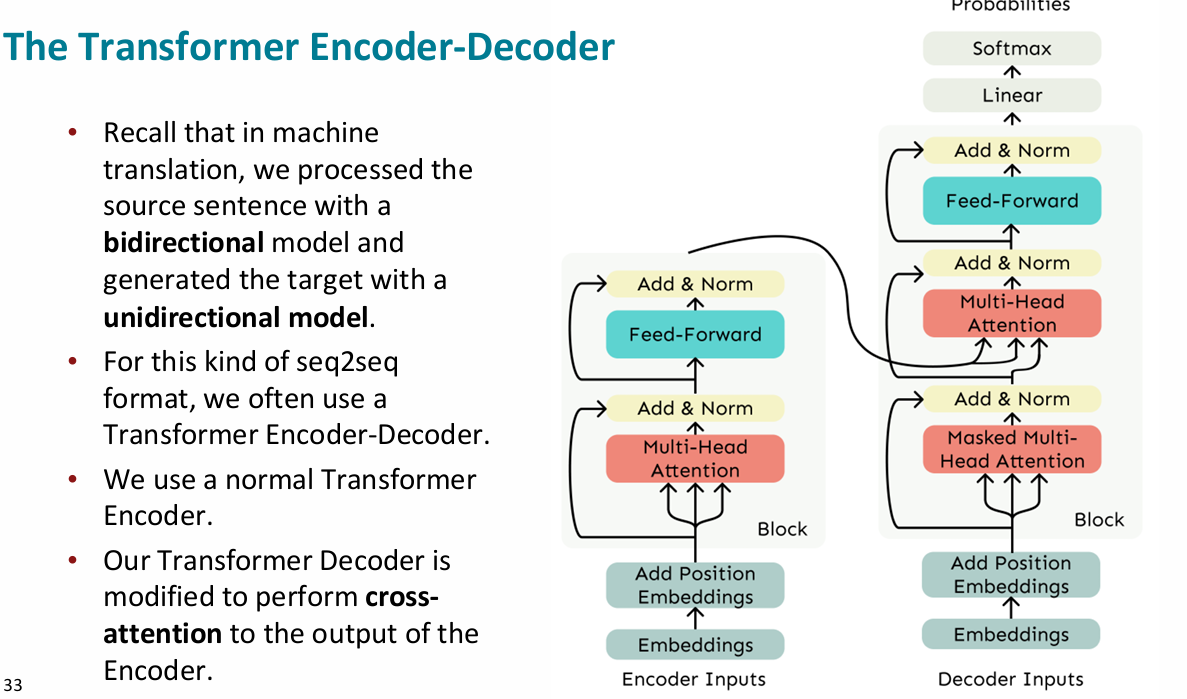
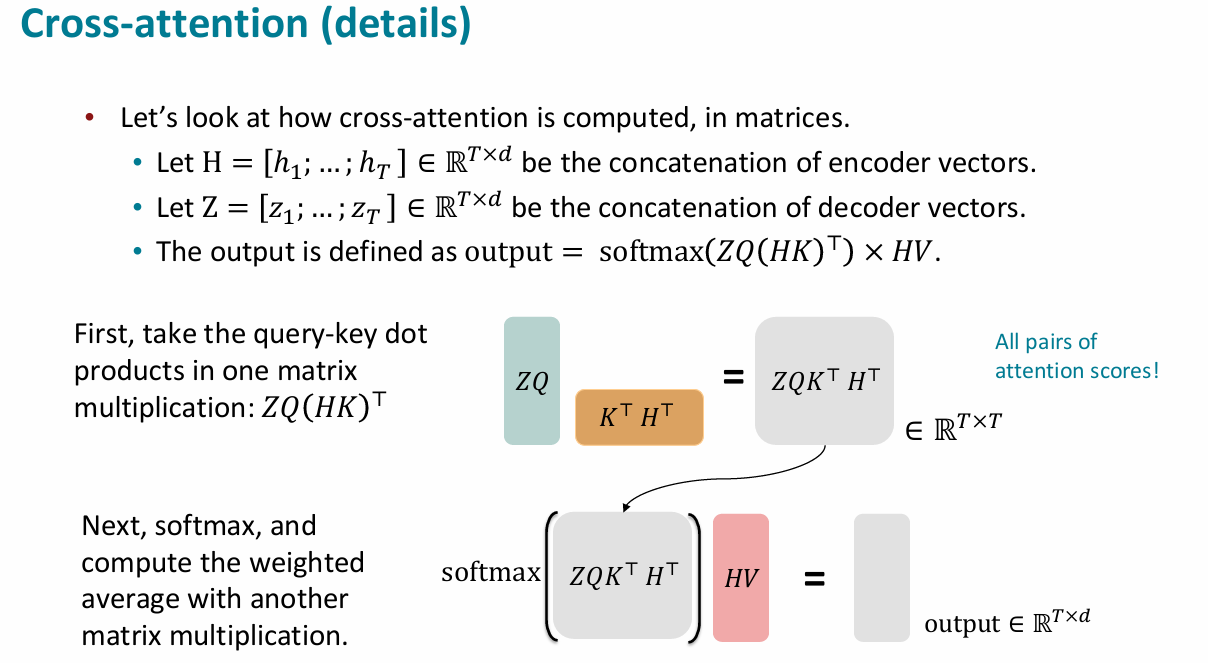
cross details
- 矩阵形式
note
- 对于多维张量的softmax定义

- 另一种解决位置编码的方法(直接改变)

(我们应该将更多的注意力投向相对较近的位置) - 层标准化
- Further work shows that this may be most
useful not in normalizing the forward pass, but actually in improving
gradients in the backward pass - 寻找偏置和系数那一步或许实际上不太重要甚至有害
- 两种标准化的比较:BatchNorm是对一个batch-size样本内的每个特征[分别]做归一化,LayerNorm是[分别]对每个样本的所有特征做归一化。这样就好理解了。
- Further work shows that this may be most
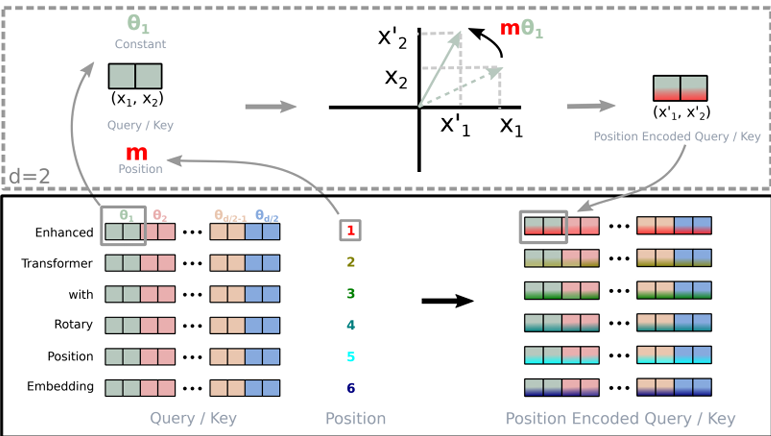
RoPE( Rotary Position Embedding)

elu非线性函数:

- 对relu的线性存疑solution:只有当所有输入永远为正(实际中几乎不可能),ReLU 才会退化为纯粹的线性函数。但这种情况在训练过程中几乎不会发生,因为网络参数会不断调整以适应数据分布。
- 更有计算效率的搞法
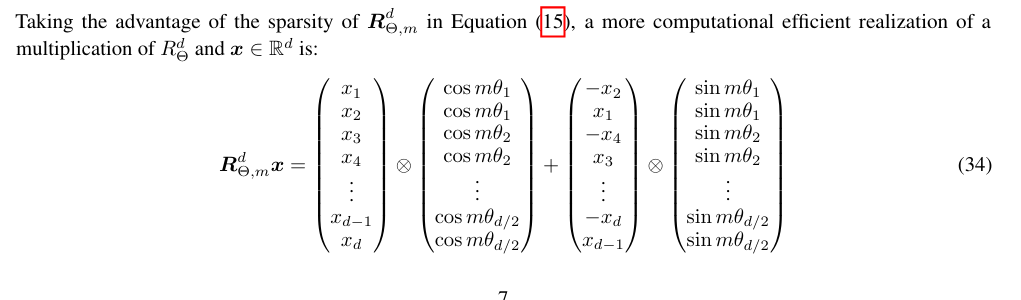
杂

default final project(gpt-2)
- Paraphrases are “rewordings of something written or spoken by someone else”
- GPT (Generative Pretrained Transformer) models are built on the idea of using massive amounts of unlabeled text to pre-train a decoder-only Transformer architecture in an unsupervised manner, then fine-tuning
on downstream tasks. - gpt-2相对1就是规模更大、训练数据更多更杂、未经下游微调的效果更好
单词
precursor :前体
magnitude:巨大、重要性、
单词
revisit:再次审视、重游
egregious:惊人的、过分的
leaderboard:排行榜
gamesmanship:伎俩、策略
provoke:激起、挑衅
augment:增大、补充
annotate:注释
fuzzy:模糊的
invarient:不变的
rotation:也指坐标轴的旋转和旋度等
ubiquitous :普遍存在的
verbose:冗长
non-monotonic :非单调的
affinities:密切关系
leverages:影响力、充分利用
conjugate:共轭、结合
orthogonal:正交的、直角的
radical:根本、极端、根式
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.


