
csapp_cachelab
第五章(优化程序性能)
- 编译器优化的限制

generally useful optimization
- code motion:减少计算的频次,把相同的重复计算移动到循环外
- reduction in strength:将昂贵的计算换成更便宜的(如乘变加和移位)
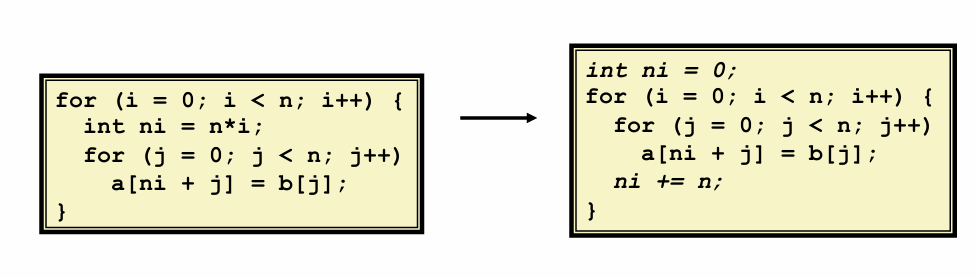
- share common subexpressions:重复使用部分表达式
Opmization on Blocker
-
#1: Procedure Calls

- 实际上该代码的运行及其低效:每次循环都算一次strlen(s),程序是平方增长的
- 前面的编译器优化程度开高点都行,但是这个优化不了:因为编译器必须假定函数调用是黑盒,它无法确定该函数的调用会产生什么副作用
- 可以内联来搞,也不算太good
-
#2:Memory

- 编译器不能确定有无别名(aliase,即两个变量指向同一片地址),所以只能一遍一遍地从内存中读出来,算完再放回去
-

-
aliase实际上在c中很容易发生:可以对指针进行运算操作,同时直接访问存储结构,程序员能做的就是习惯引入局部变量
Exploing Instruction-Level Parallelism (指令级并行)

- benchmark的两个小技巧:使用抽象的data_type 和operation实现代码复用

- superscalar processor:先读取一系列指令然后根据依赖关系算
- 流水线:(原本3*3个周期下降到7个周期)
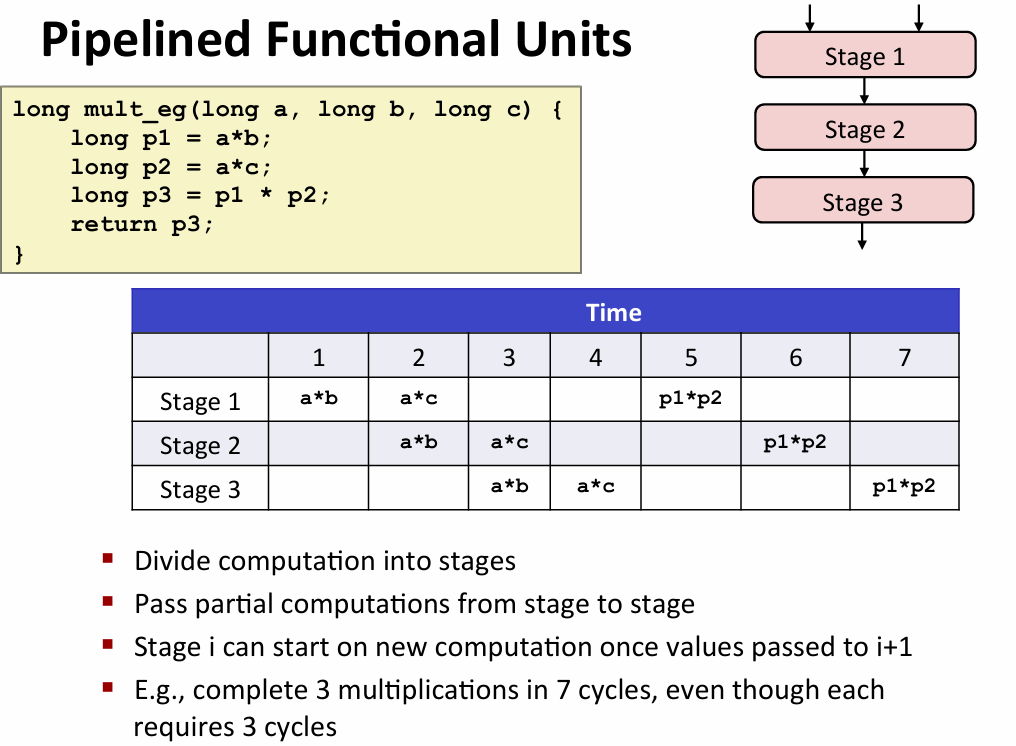
- 但是有些时候你的计算过程具有顺序依赖性(时间取决于latency(执行时间))
- way:loop unrolling and reassociation

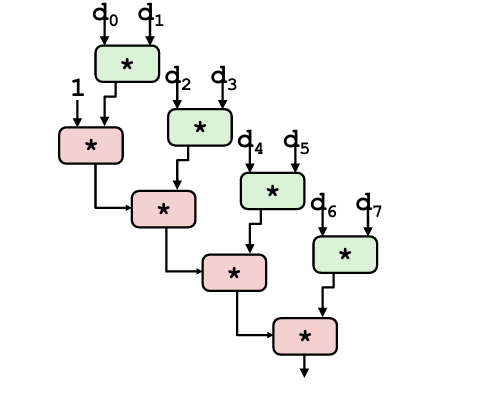
- 事实证明这样极其有效,但是坏消息是计算浮点数很可能不能这么干
- way:loop unrolling and reassociation
- unrolling and accumulating的推广

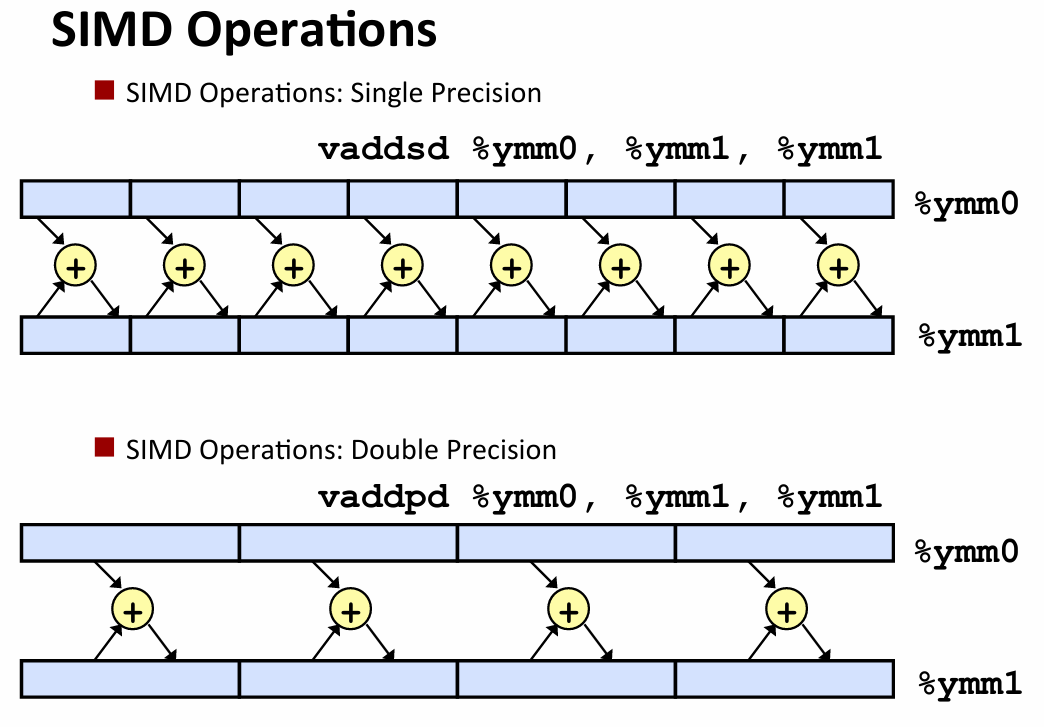
- 还有一种矢量加法优化器
- 分支预测:猜某个分支然后运行(但是并不真正改变寄存器和内存的值)
memory hierarchy
storage technologies and trends
- RAM(random-access memory):一组芯片,单元为cell(one bit per cell),许多RAM就形成了内存,分为SRAM和DRAM
- sram更复杂,高速,无需错误检查什么的,很贵,当缓存用
- dram用作主存,frame buffers,需要refresh(持续供电以保持数据)
- dram sram都是volatile memory(易失内存,断电丢失)
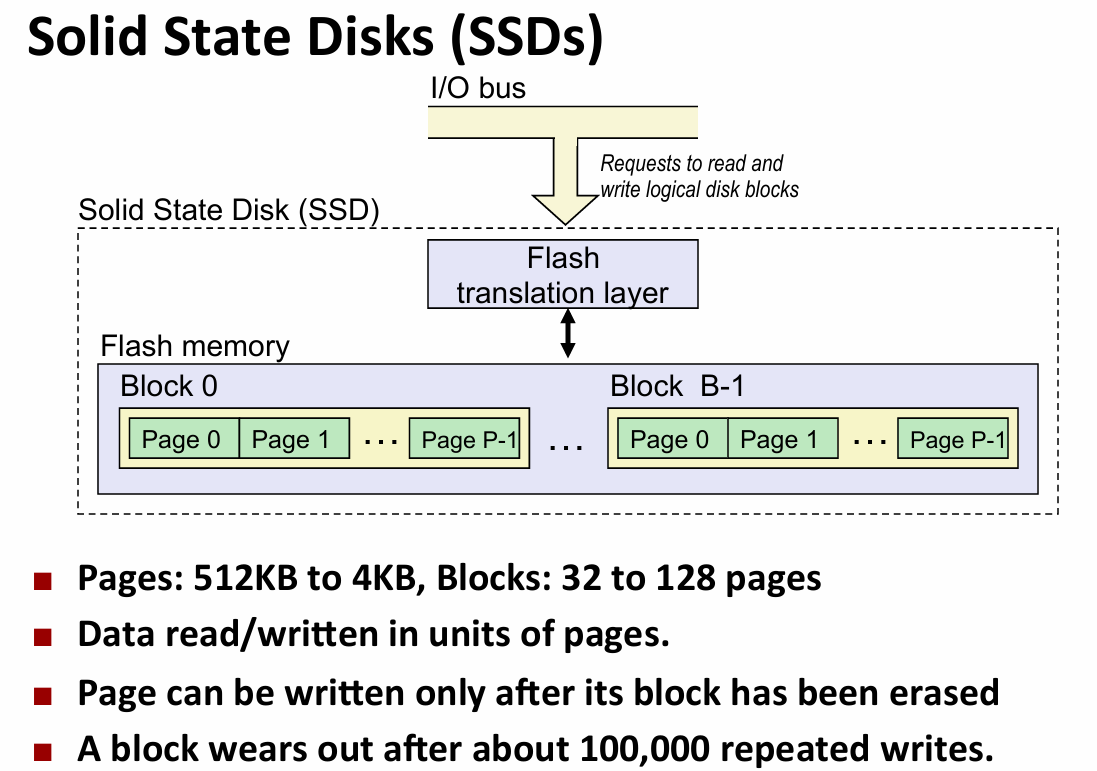
- non volatile:ROM(read-only memories)闪存也是一种ROM
- 用处:存bios等,solid state disks(SSD),disk caches
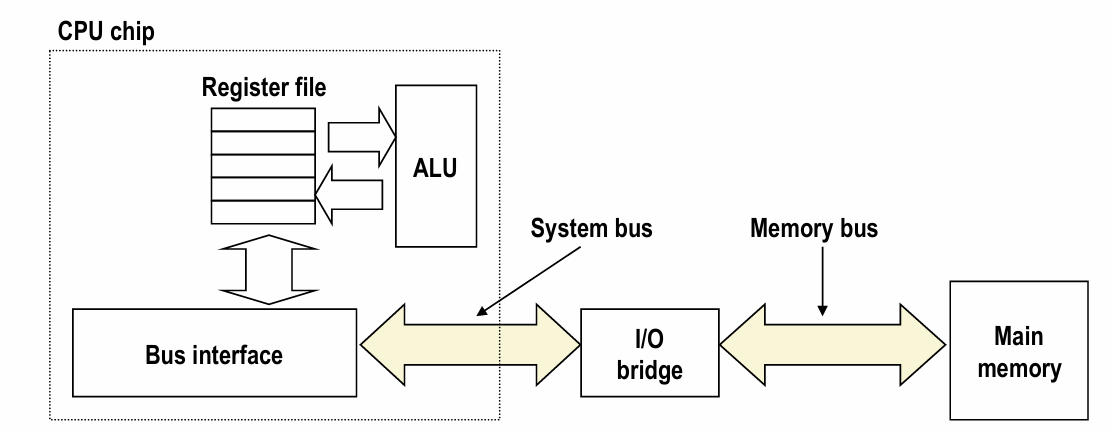
-
load operation: movq A %rax
- cpu 把地址放在memory bus上
- 主存从bus上读取A,检索相应数据x,再放回bus
- cpu从bus上读取并将其复制到寄存器中(store基本同理)
-
磁盘:
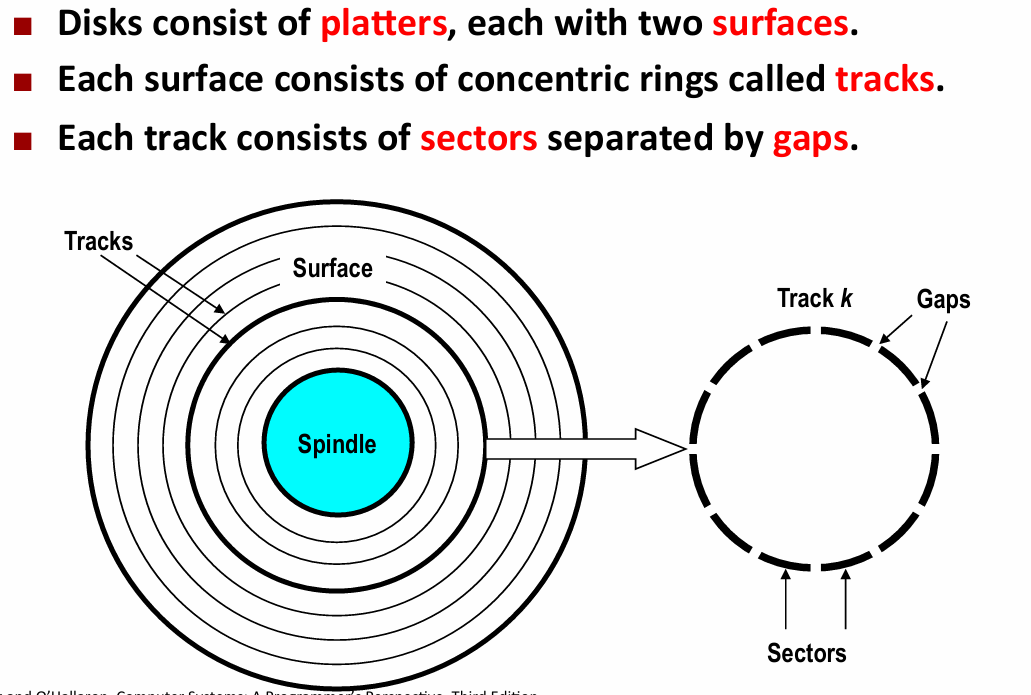
- 容量:经典虚标(用十进制来算,密度:长乘宽)

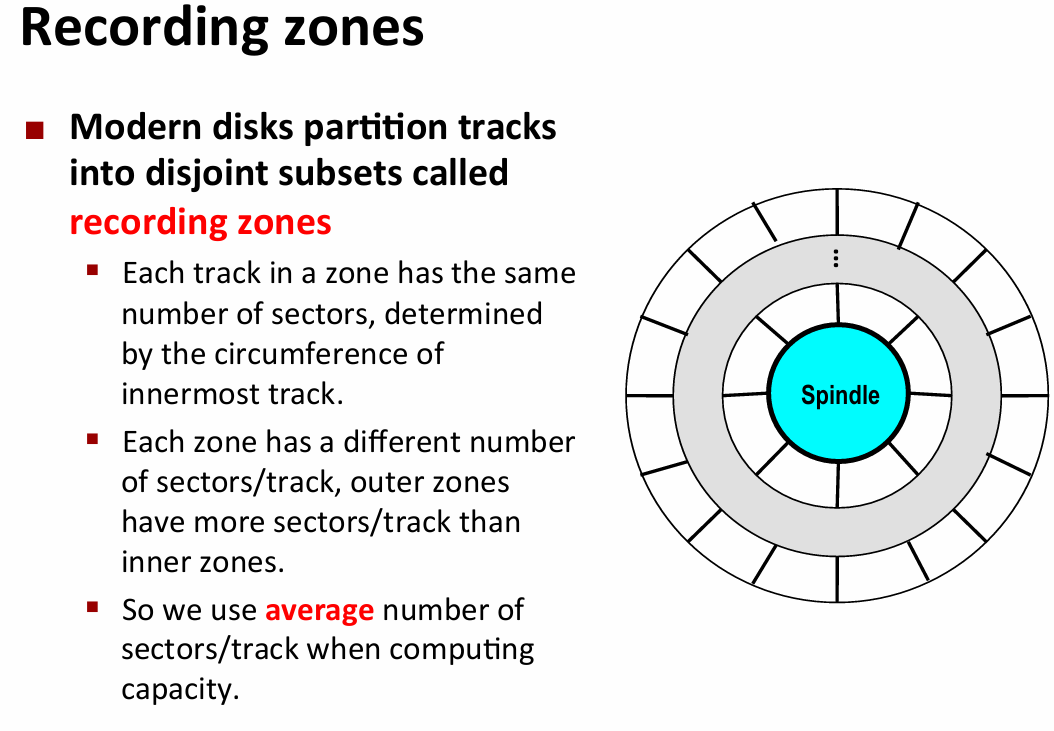
- 磁盘访问
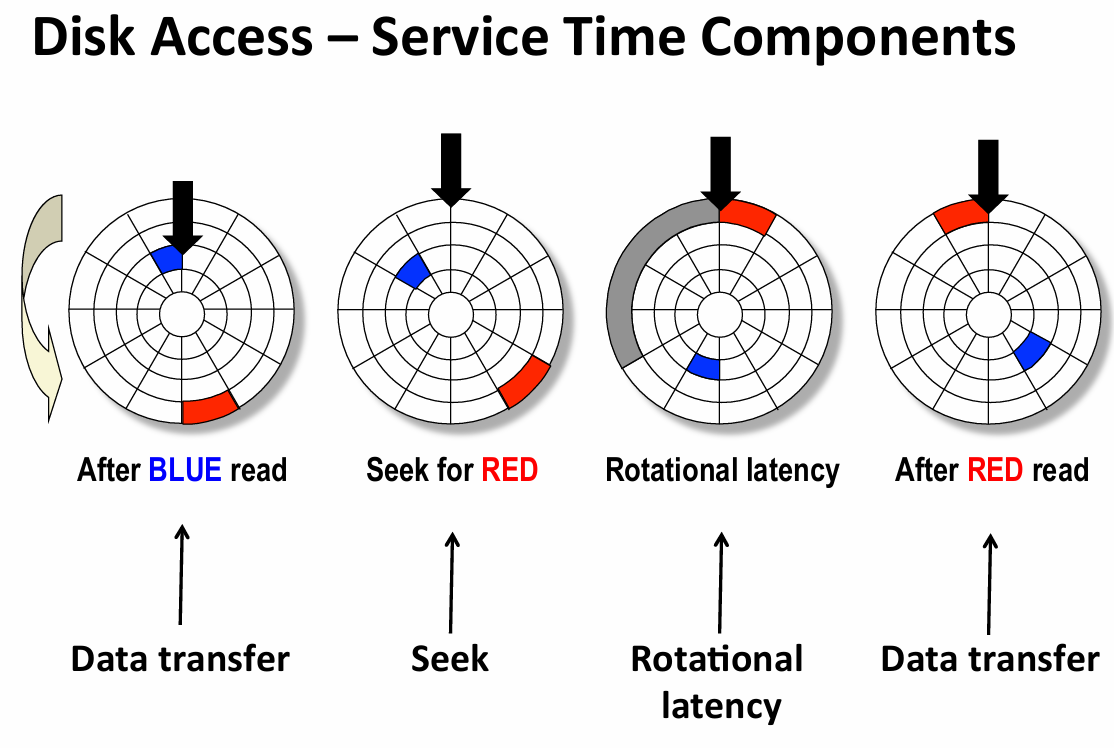
- 主要时间瓶颈是seek和rotation latency
- 现代磁盘为cpu提供了简单逻辑块抽象(sector),对其进行编号,然后控制负责维护从逻辑块到实际物理区域的映射
- 有一部分cylinders是用来备用的,故障的时候把当前数据复制到备用的就可以接着用,所以format capacity 要小于actual capacity
- 从磁盘中读取:
- cpu初始化了一个三元组:(指令 逻辑块编号 目标内存地址)并发送给磁盘控制器
- 磁盘控制器读取并存放到内存中,当它读完了才会发送一个interupt信号提示cpu读取完毕
- 这种设计可以让cpu在等待读取完成的同时干别的
- 容量:经典虚标(用十进制来算,密度:长乘宽)
locality of reference
- principle of locality: Programs tend to use data and instructions with addresses near or equal to those they have used recently
- temporal locality:最近引用过的数据有可能在将来再次被引用
- spatial locality:引用过的数据的相邻位置的数据更有可能被引用
- 作为程序员最重要的能力:qulitative estimation of locality

- 步长为1的线性访问模式,非常好的空间局部性
caching in memory hierarchy
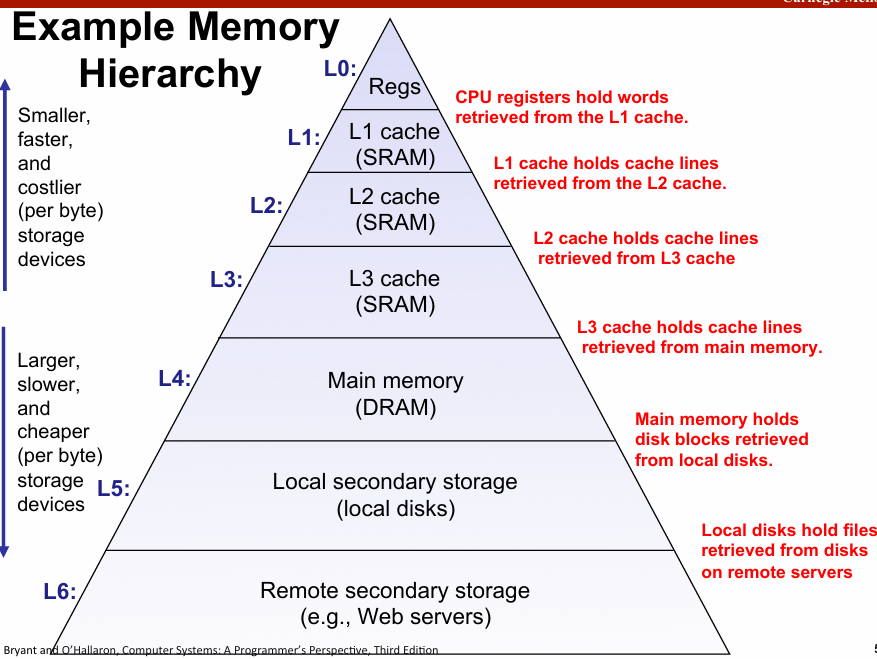
- 缓存允许我们以最高层的速度访问处理最底层容量的数据
- 数据在缓存中:缓存命中(hit),反之则是(miss)

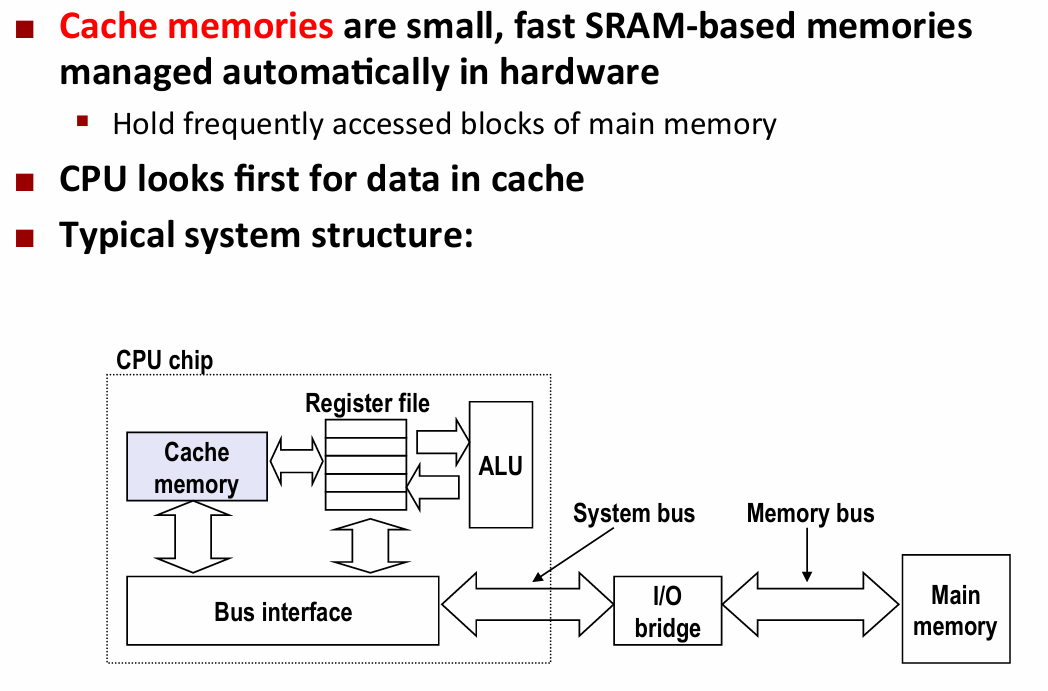
cache memories
Cache memory organization and operation
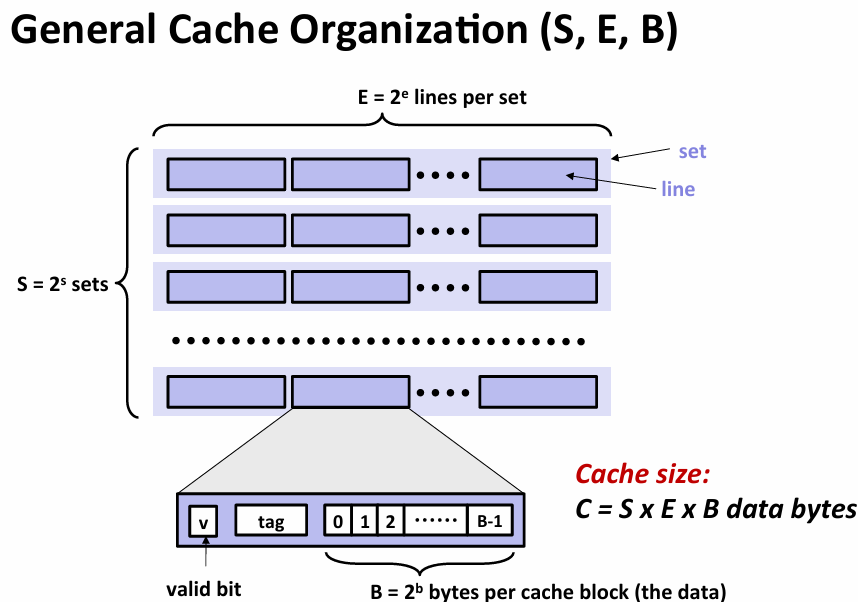
- read
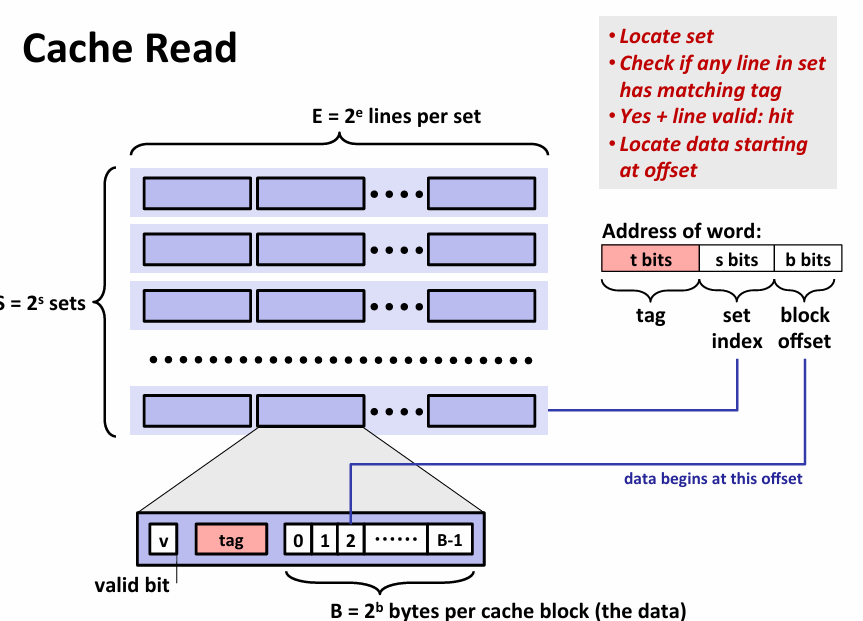
- 当e=1时,称direct mapped cache,实际上相当之低效
- 块的设计初衷就是为了利用空间局部性,但是大小设计相当棘手(trade-off)
- 缓存中的替换:很多种算法,最近最少,你要重新写回内存因为可能发生变化
- write

- 衡量缓存的指标

performance impact of caches
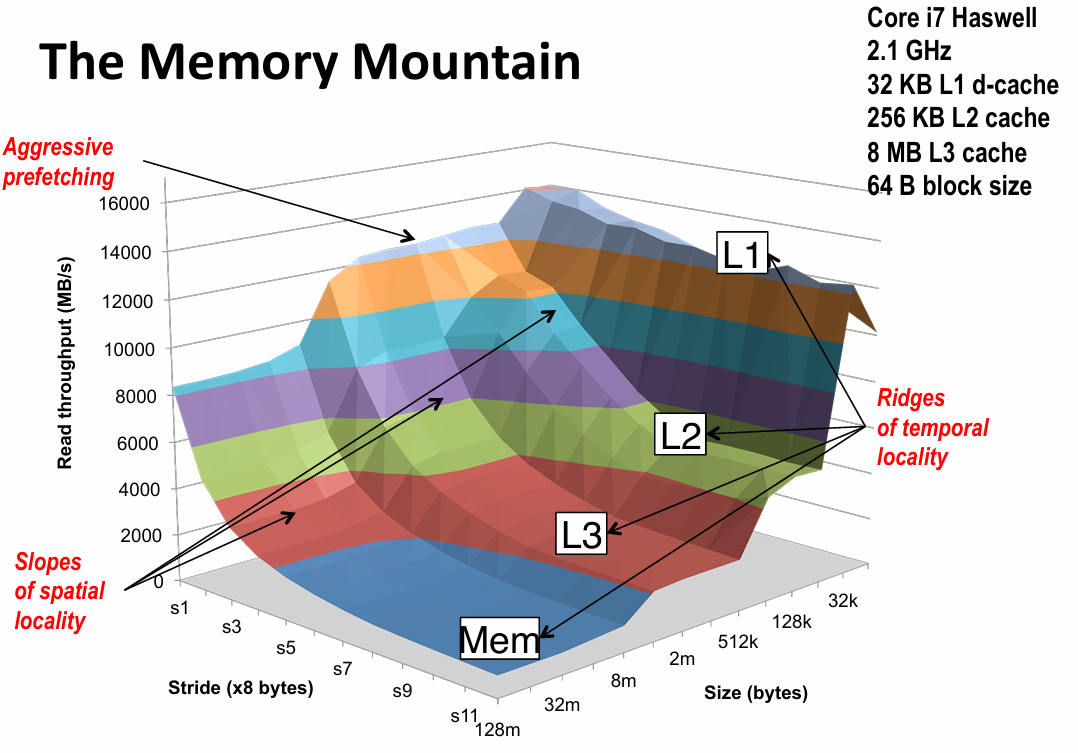
- memory mountain
- read throughput:number of bytes read from memory per second
- memory mountain:measured read throughput as a function of spatial and temperal locality

- 增大stride:减小空间局部性,增大size:减小时间局部性(因为size更大了之后高级缓存放不下了)
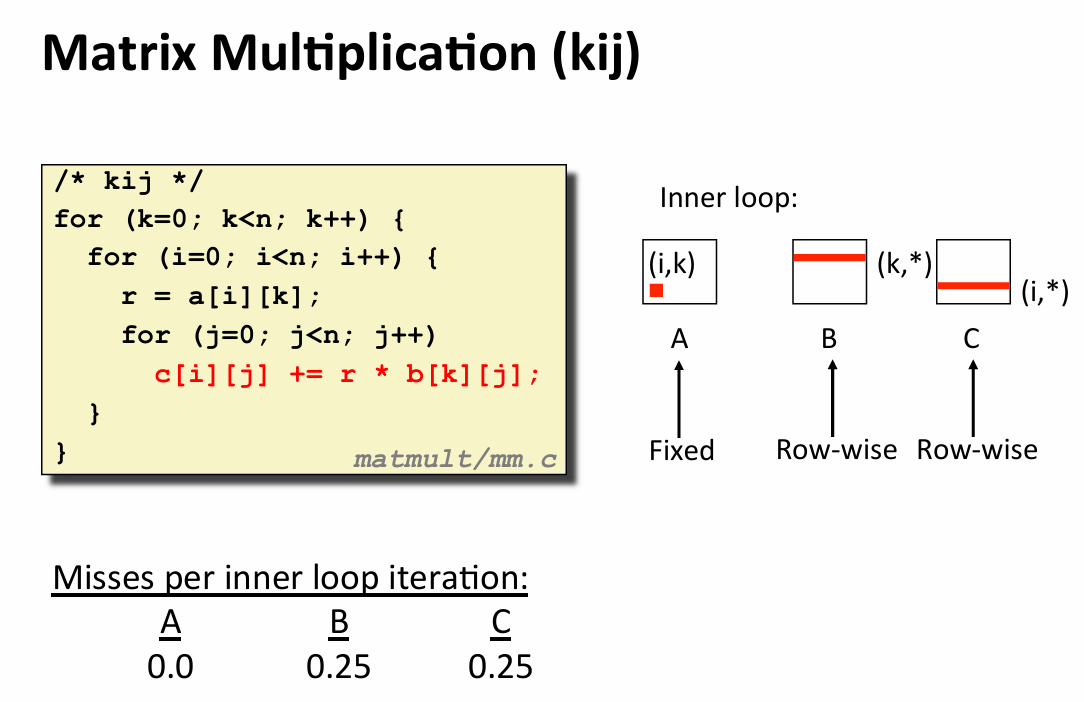
- rearranging loop for better spatial locality
- 这种有额外的存储开销:但是在现代系统中写比读容易得多,不会成为瓶颈
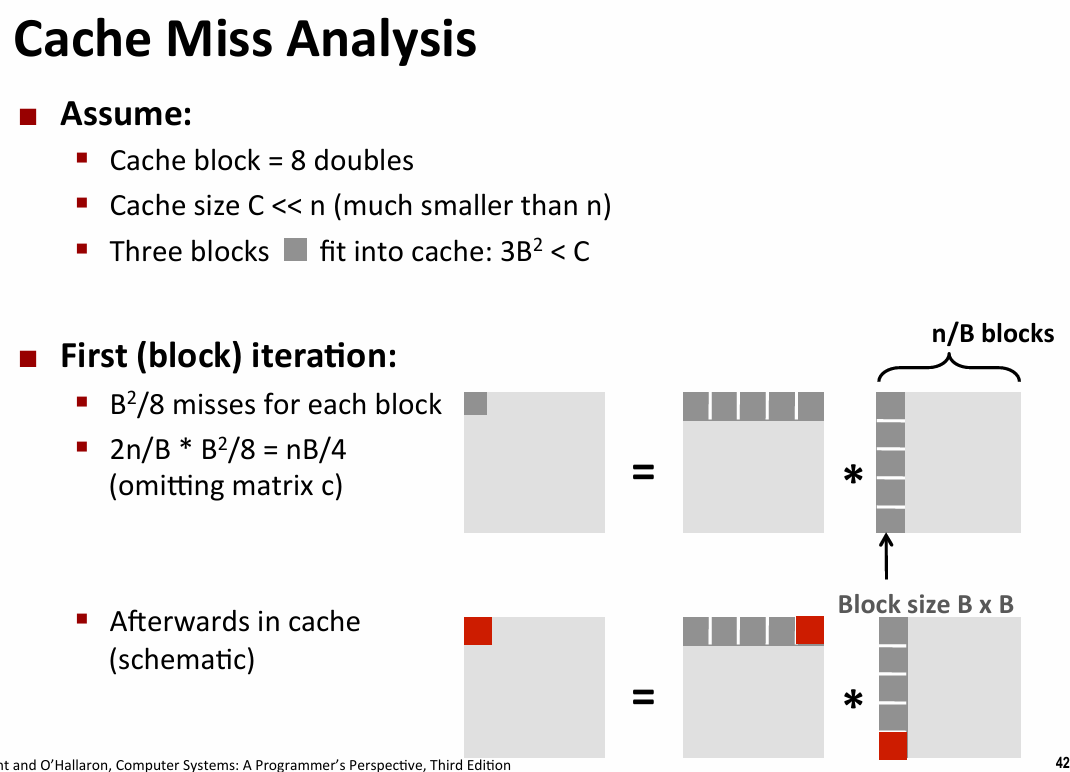
- blocking
cachelab
- getopt():包含在unistd.h中的函数,用于解析程序的命令行参数
int getopt(int argc,char* const argv[],const char* opstring)- opstring:"abc:"表示-a -b普通选项加上一个必须有参数的-c选项
- 两个冒号为可选参数

- 模拟内存访问
|
- 针对特定size的矩阵的block优化
void transpose_submit(int M, int N, int A[N][M], int B[M][N]) |
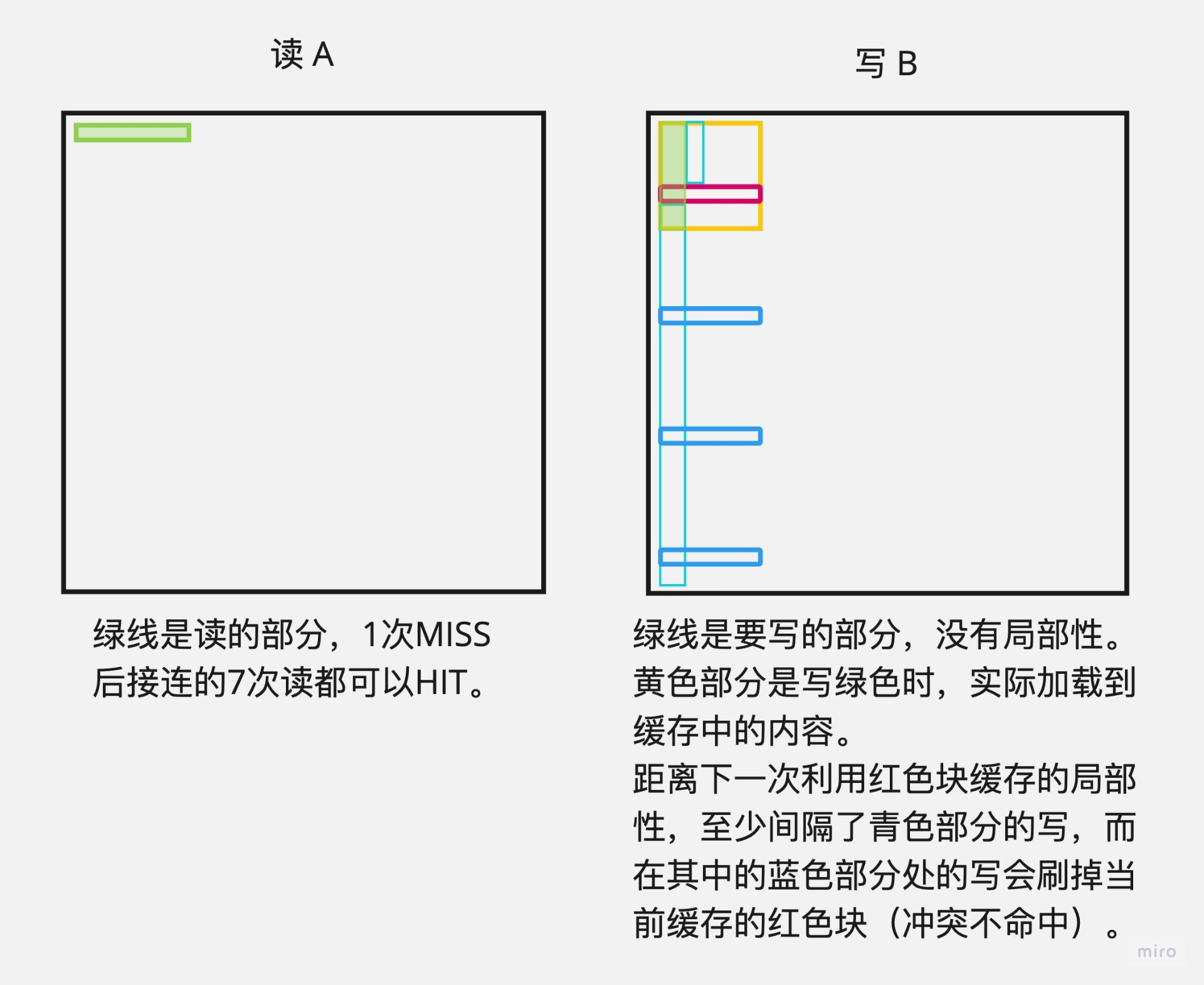
- 其它的分块思路:先分8*8再在小块里面分4*4
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.


