
csapp_malloclab
virtual memory:concept
address space
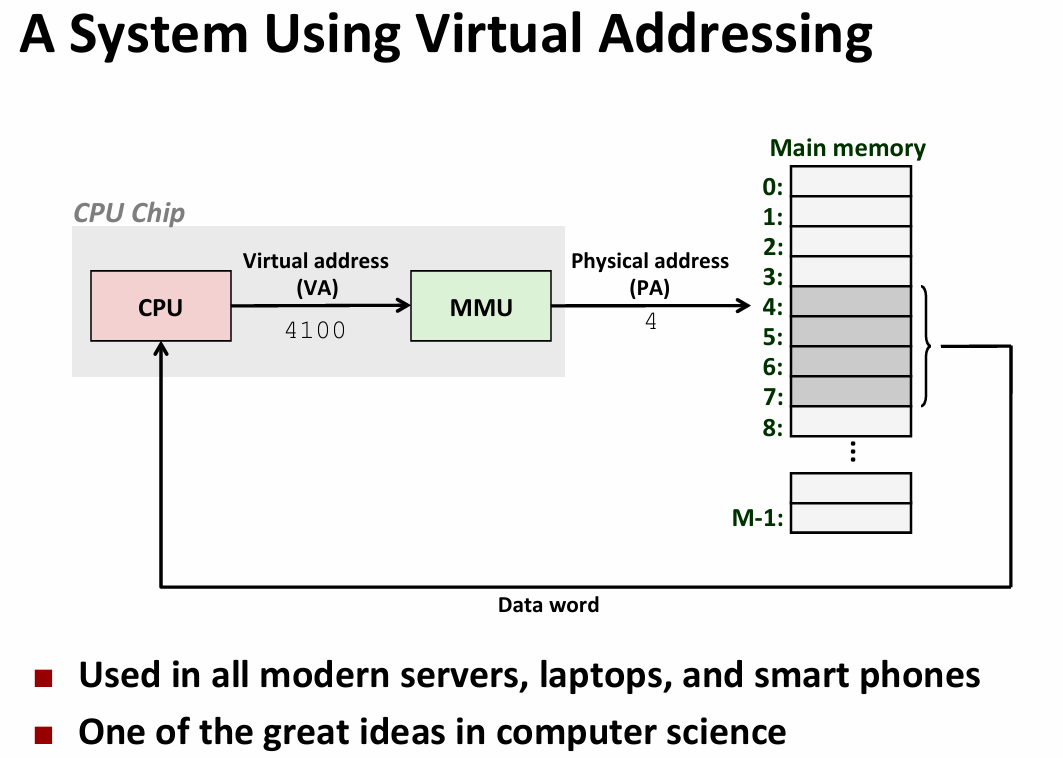
- linear address space:有序连续非负整数集
- virtual address space:set of N=2^n virtual addresses
- physical address space:set of M=2^m physical addresses
- why VM:
- use dram as a cache for parts of the virtual address space
- 简化内存管理
- 隔离地址空间
vm as a tool
for caching
- 概念上讲:vm就是n个连续的在磁盘上的字节数组
- 硬盘上的数组内容缓存在物理内存(dram cache)中
- 这些缓存块称为page(P=2^p),通常比高级的缓存大得多
- 需要一个复杂得多的映射函数
- 总是使用write-back rather than write-through
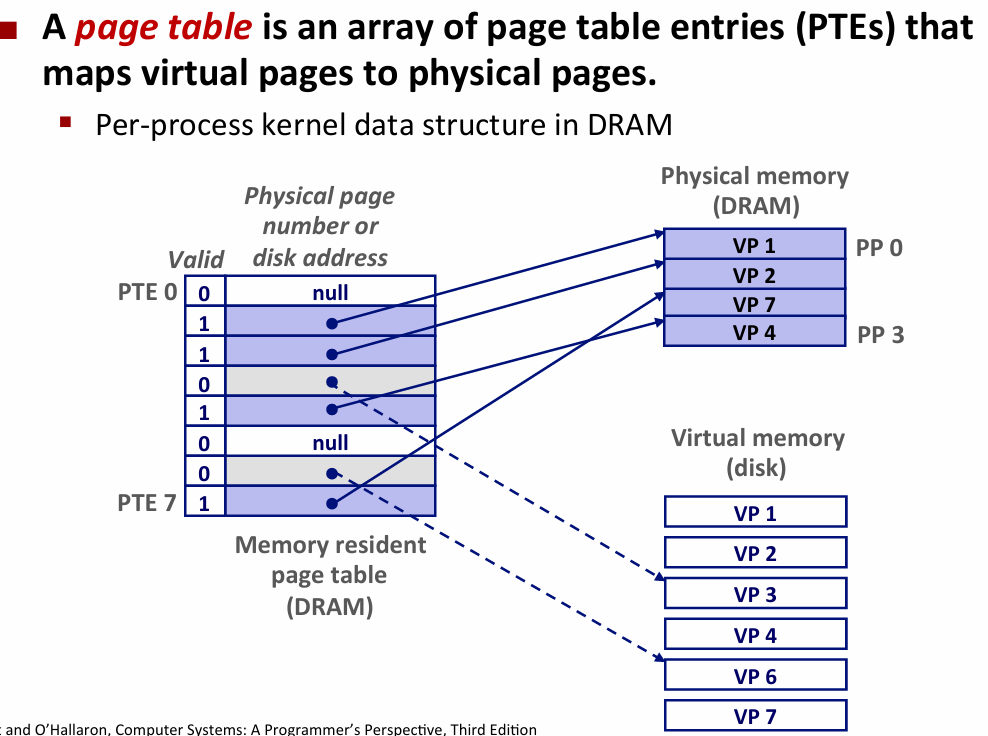
- page miss(就是缓存未命中)cause page fault(an exception)
- 解决:page fault handler 选择victim换掉了之后重新执行指令
- waiting until the miss copied to the physical memory is known as demand paging
- 看起来很低效但是locality
- 在任何时间程序倾向于访问一个活跃的页集合:working set
- 如果sizeof working set<main memory:性能相当好
- 多线程情况下sum>main memory:thrashing(抖动)页来回切换变差
vm as a tool for memory management
- 每个进程有自己的虚拟内存,可以将内存视为简单的线性地址空间
- 可以将不同进程的虚拟内存映射到同一个物理内存(sharing code and data)
- 链接的时候可以认为代码总是从相同的地址开始
- loading:allocate VM for .code and .data,create PTE and set all invalid
for memory protection
- extends permission bit :x86-64系统中的高位会用于设置权限(可读,可执行之类的),MMU will check the bit on each process
- 这实际上就可以防护类似code injection 之类的攻击
adress translation

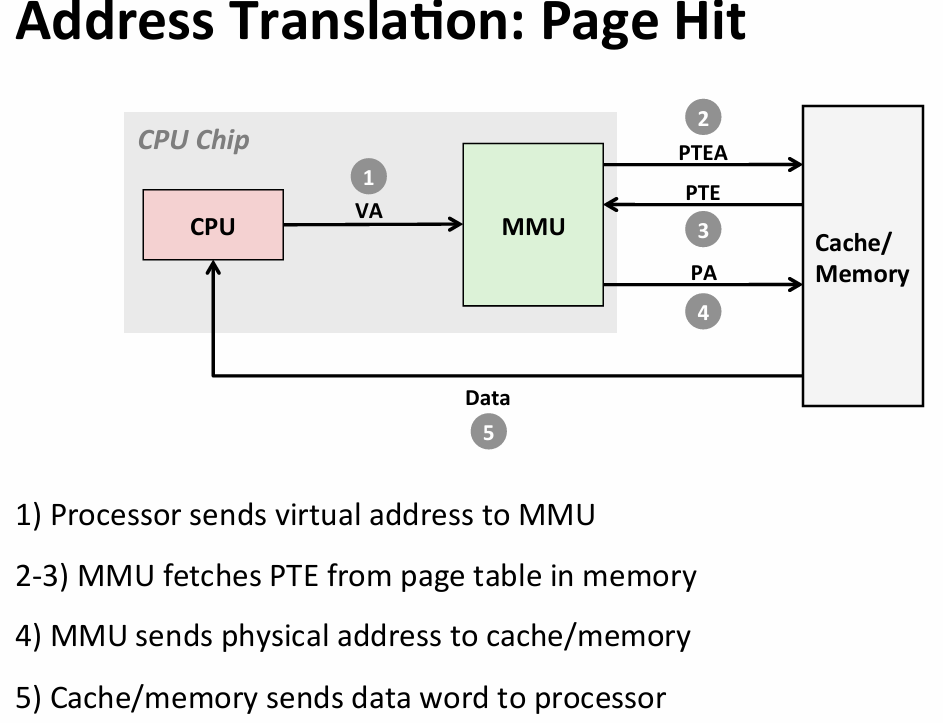
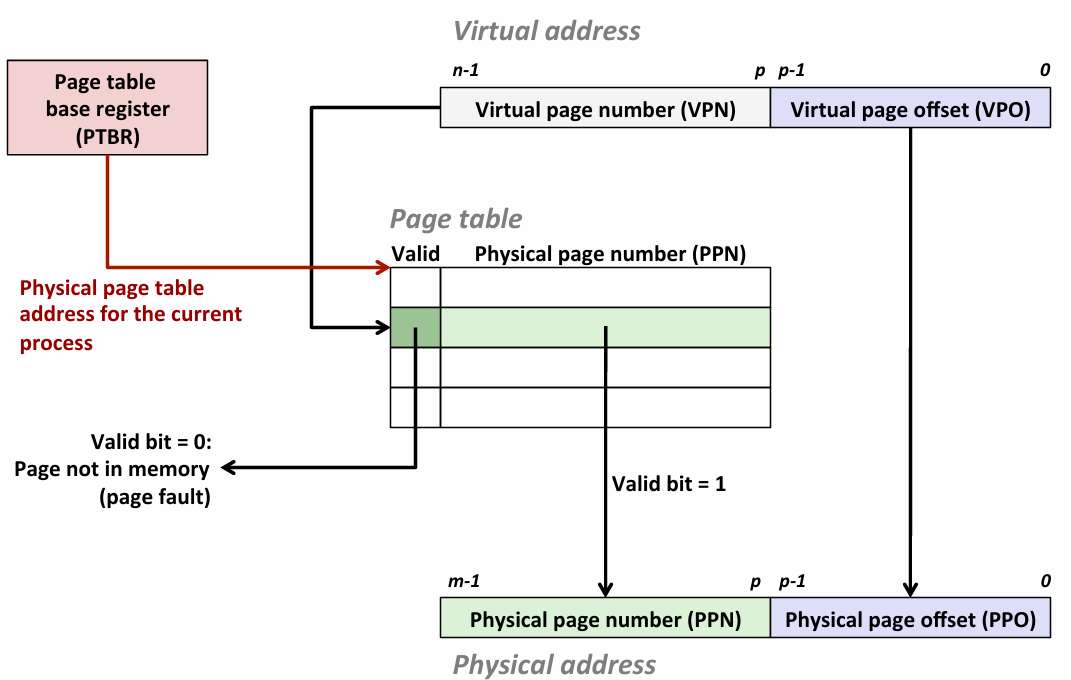
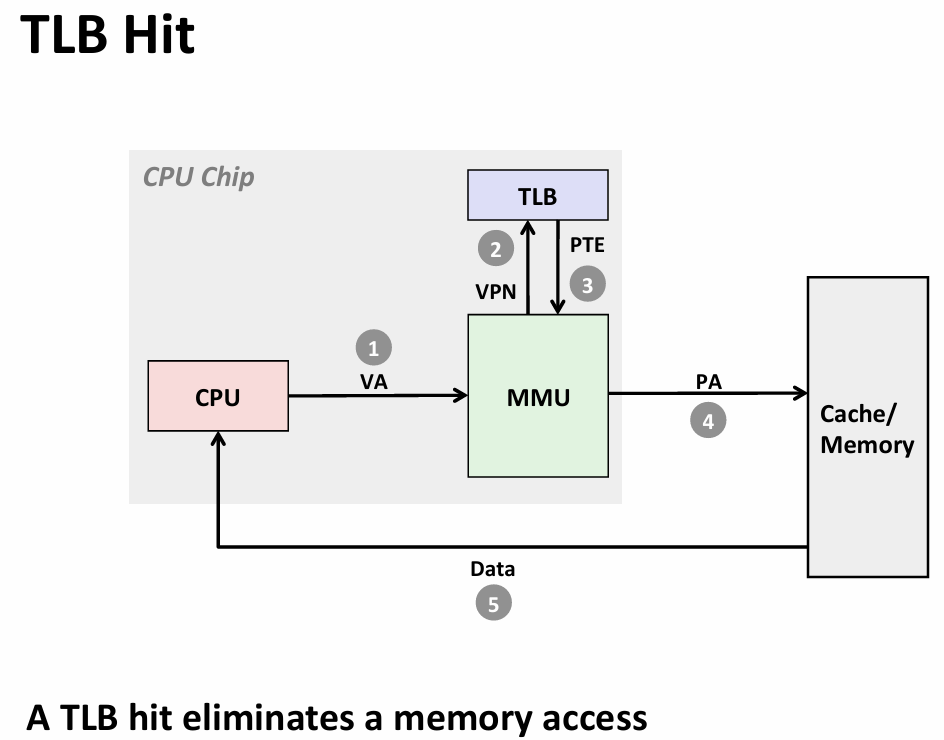
- speed up translation with TLB(translation lookaside buffer)
- PTE(page table entry)在l1缓存中
- small set-associative hardware cache in MMU
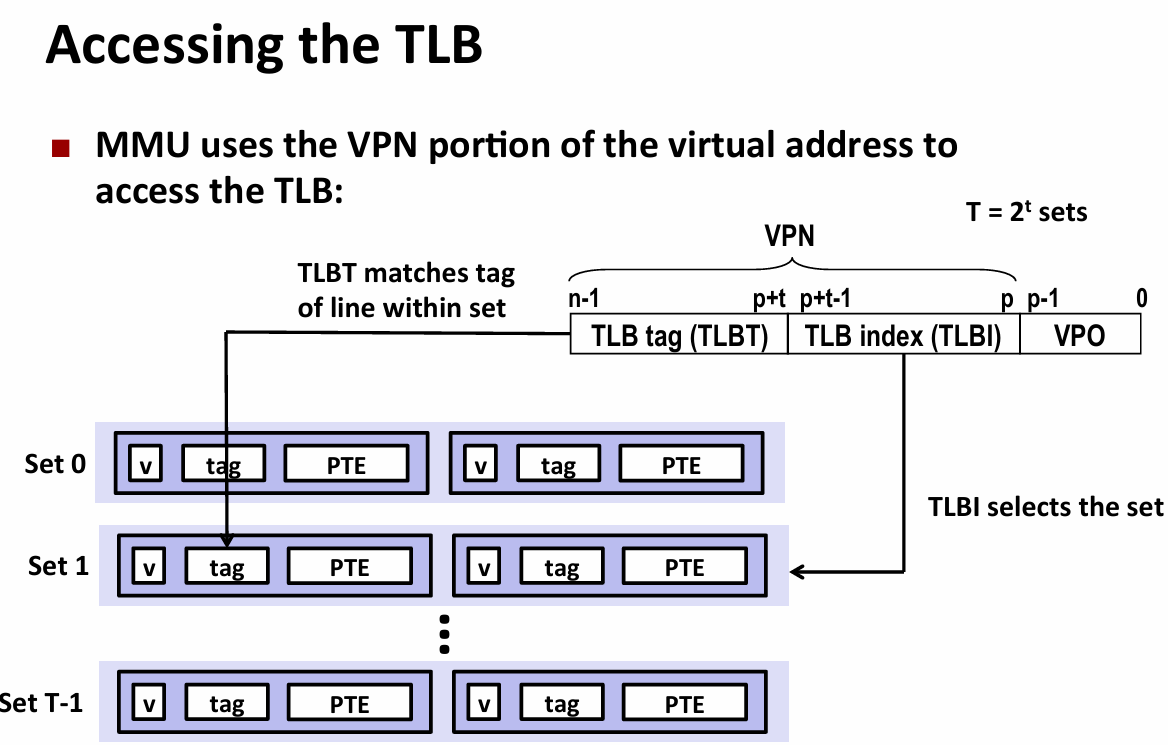
- 然而:一个页表全存起来太大了,solution:multi-level page table
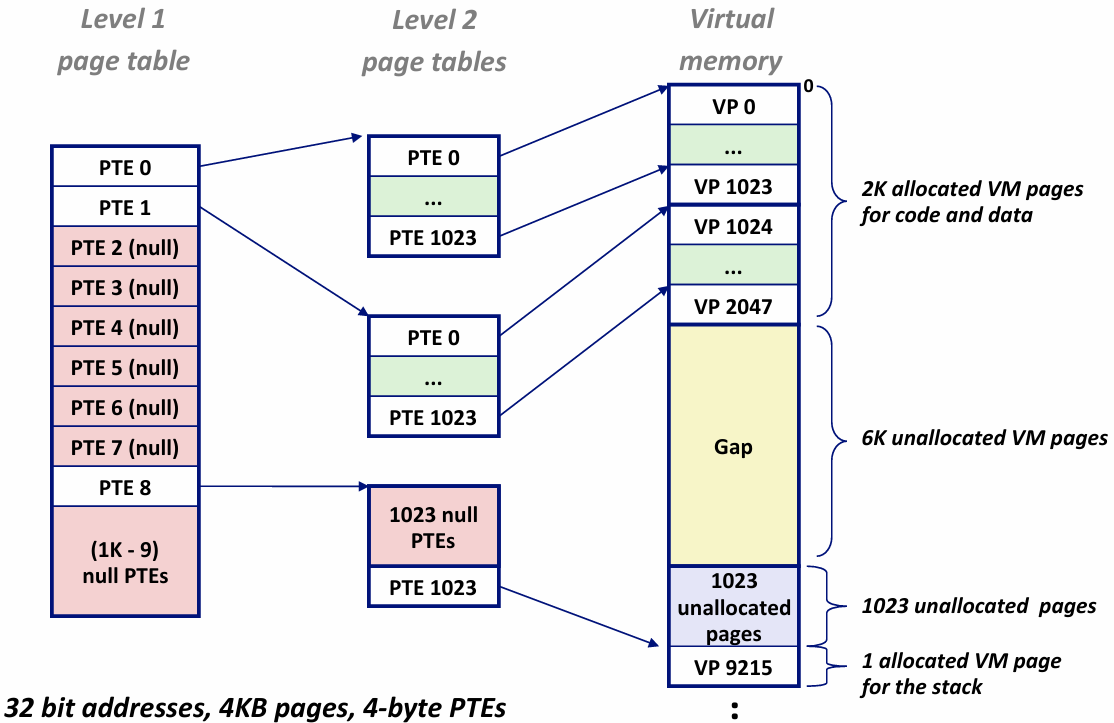
- 可以搞k级页表,第i级页表指向下一级某个页表的表头地址
- 一级表全部映射,数组的访问方式也快
virtual memory:systems
simple memory system example

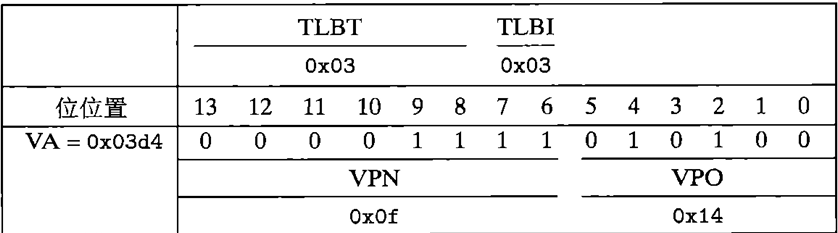
1.MMU取VPN
2.查看TLB中对应idx位是否缓存命中(查看TLBI位并检测TLBT)
3.若命中,直接返回相应的PPN,否则,从主存中加载对应的PTE
4.链接得到物理地址发送给缓存
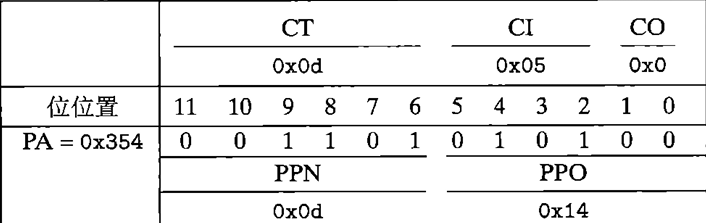
5.缓存检测是否命中
corei7
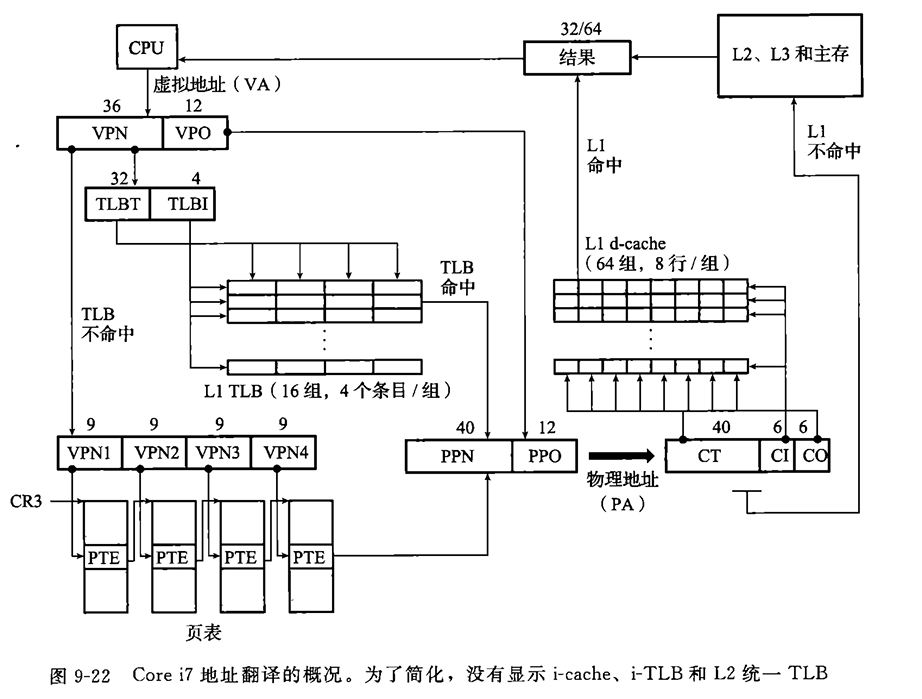
翻译加速小技巧:
- 设置高速缓存的索引位和偏移位之和与VPO相同
- 地址翻译的同时就把VPO发给缓存,让缓存去找
- virtually indexed,physically taged
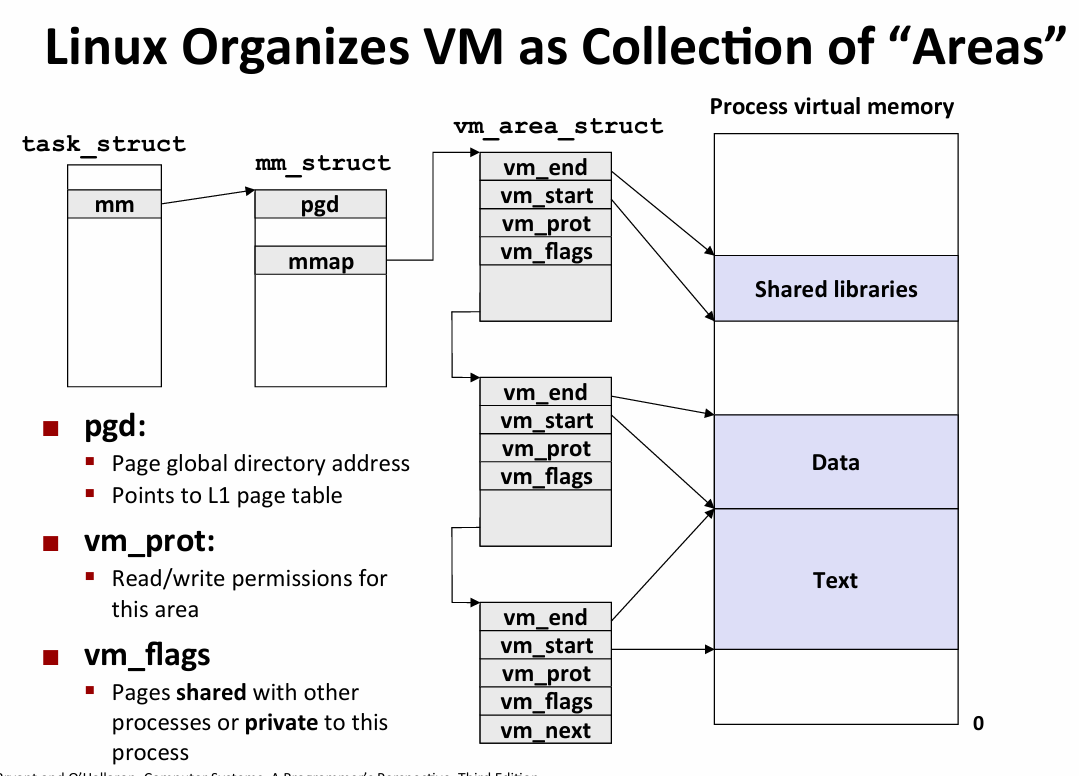
linux将虚拟内存组织为区域(area 也叫segment):已存在的虚拟内存连续片
每个虚拟页都在某个区域中
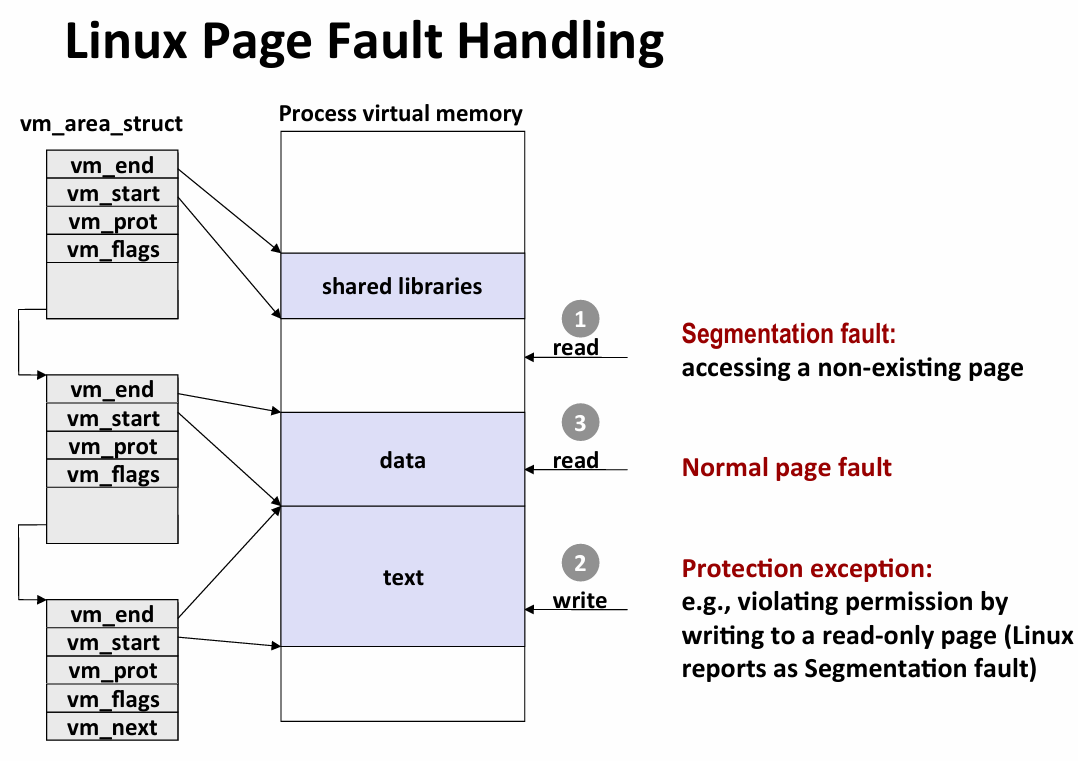
memory mapping
通过将虚拟内存区域与磁盘上的一个对象相关联以初始化该区域
- 可以被映射到普通文件或者匿名文件(内核创建,全二进制0,一旦被writen,就和别的一样了)
- 一旦被初始化就在swap files之间换来换去
- 使用内存映射的角度理解共享和私有区域
私有对象写时复制(copy-on-write):
- 私有区域的页PTE标记为只读
- 该区域标记为private copy-on-write
- 写私有页的指令会触发异常(物理内存上的一个私有区域可能被映射到不同进程的不同位置)
- handler会在物理内存中复制页并更新页表条目
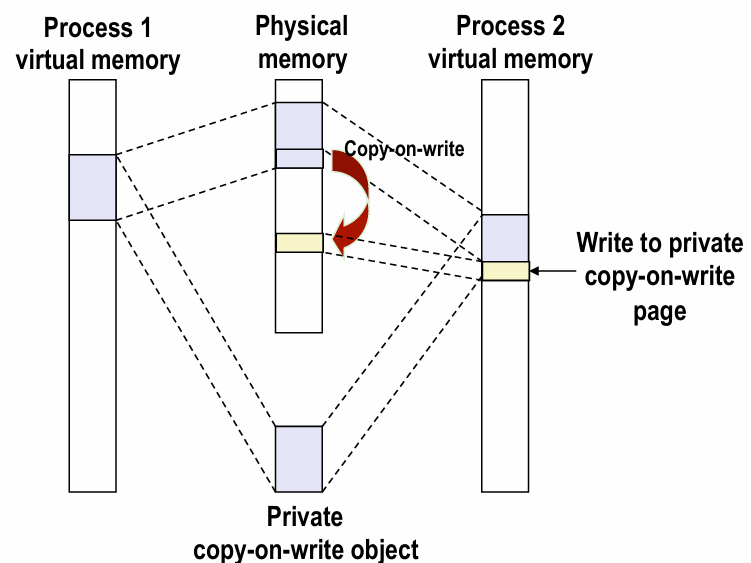
fork函数
- 创建相同的mm_struct,vm_area_struct和页表等
- 将两个进程中的所有页都标记为只读
- 所有区域都标志位copy-on-write
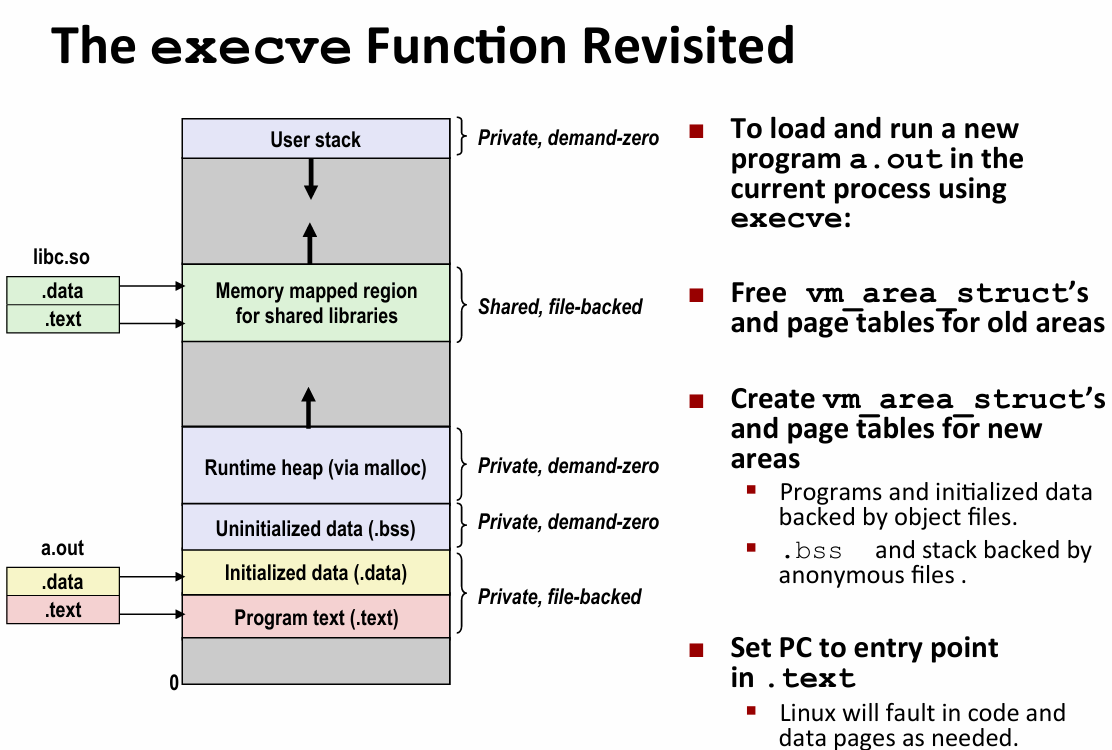
user-level memory mapping
- void* mmap(void* start,int len,int prot,int flags,int fd,int offset)
memory allocation(basic)
basic concept
- use dynamic memory allocator to access virtual memory
- the allocator manage the vm of a process known as heap
- explicit allocator(malloc and free),implicit(garbage collector)
- some constraints:
- allocator must response immediately
- can’t touch the memory once allocated
- must be aligned(8 bytes on x86 or 16 bytes on x86-64)
- the goal(performence):maximize the throughput and the peak utilization(经典时间和空间的权衡)

- fragmentation:
- internal:payload < blocksize(cause:overhead of maintaining datastructure,align)
- external:when the whole size is enough but no single block satisfied
- implementation
- knowing how much to free:多分配一小块存该空间的大小(header)

implicit free list
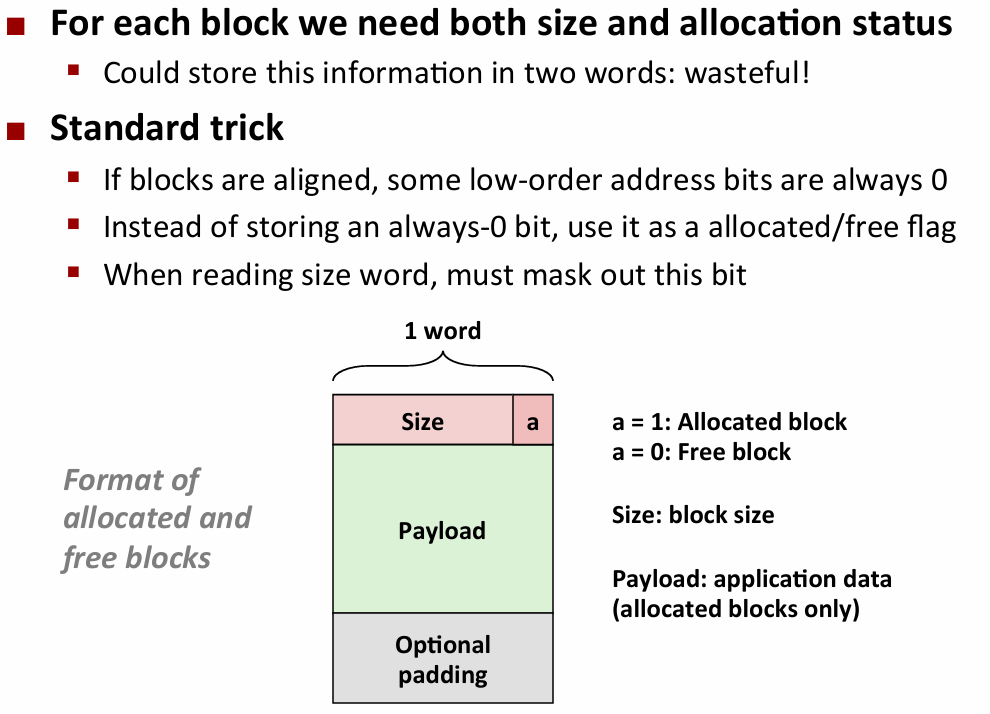
- 对齐:只要有效载荷的第一位是x的倍数就行,整个块的前面可以放信息位
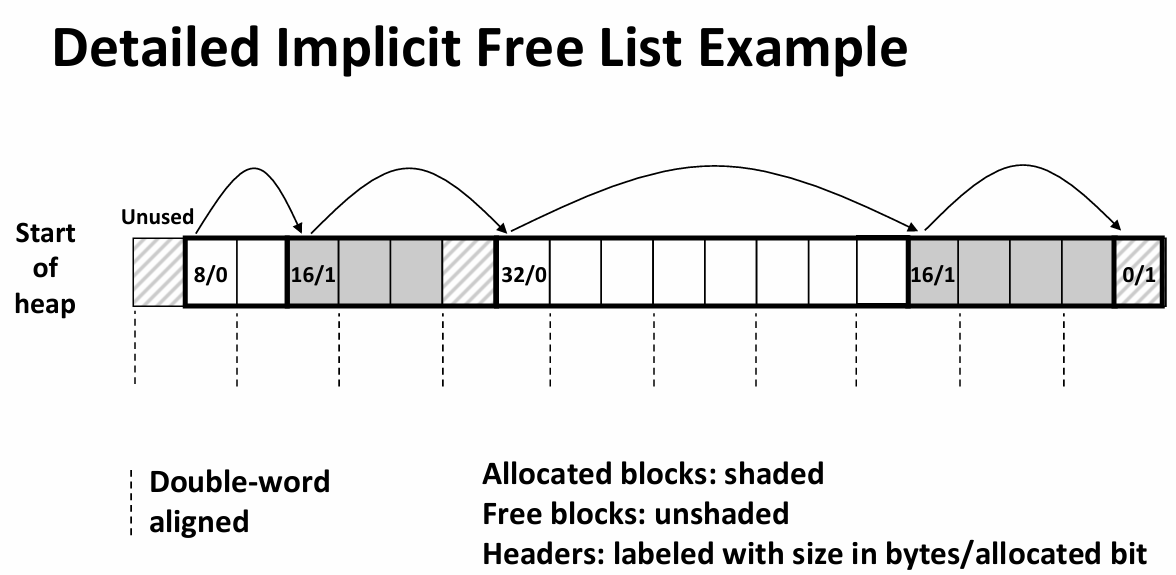
- find a free block:first fit(从头往后找第一个),next fit(从上次找的地方开始往下找),best fit(找最size最接近的)
- free的时候:仅仅擦除有效位可能导致空闲块连续,这个时候就需要查看其前后能否合并(类双向链表,把头全部复制到尾部一份)
- 改进:allocated blockes don’t need the tail, to ensure just set the second bit of free block to be the indicator
memory allocation(advanced)
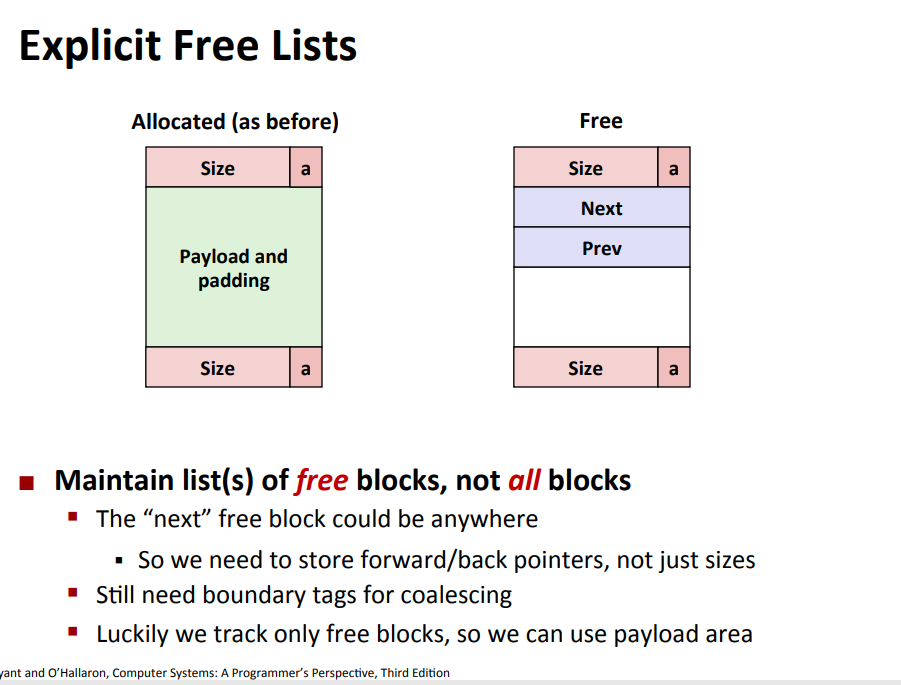
explicit list
- (maintain only the linked list of free blocks)
- 所以你的空闲块至少需要包含头尾和两个指针(free不能是更小的空间)
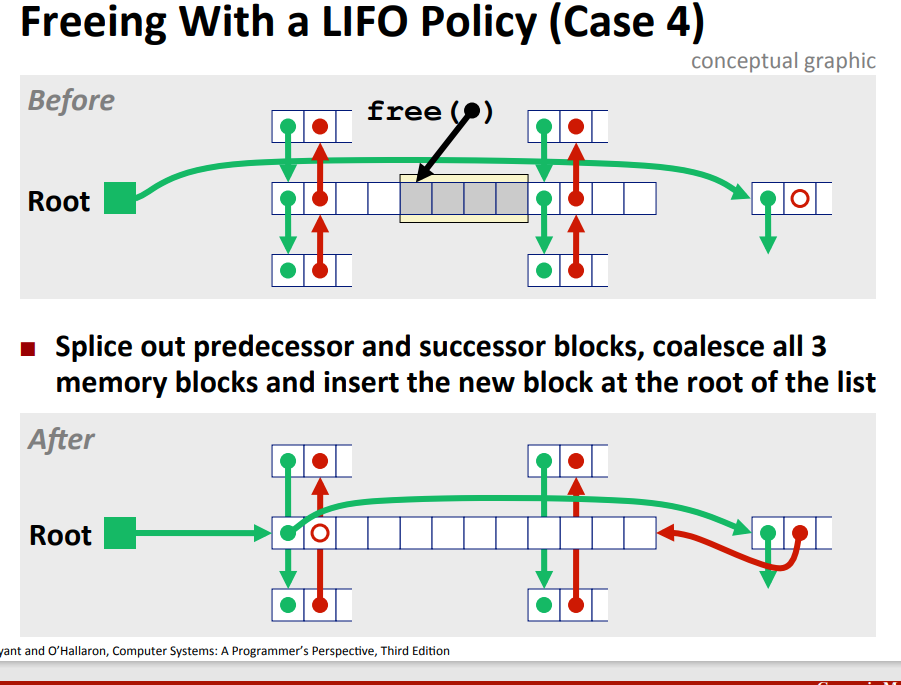
- free insertion policy:
- LIFO(last in first out):每次新free出来的块都放在free list的链表头(simple and constant time,bad fragmentation)
- 有优化,当free掉的块在某free block的后面可以直接不用更新指针
- address ordered:按地址排序插入,需要查找但是better fragmentation
- LIFO(last in first out):每次新free出来的块都放在free list的链表头(simple and constant time,bad fragmentation)
segregated free lists
- each size class has its own linked free list(class,can be single value or a range)

它在不牺牲吞吐量性能的同时提高了内存利用率(如果全是单个值的class那么等价于best fit without overhead)
garbage collection
-
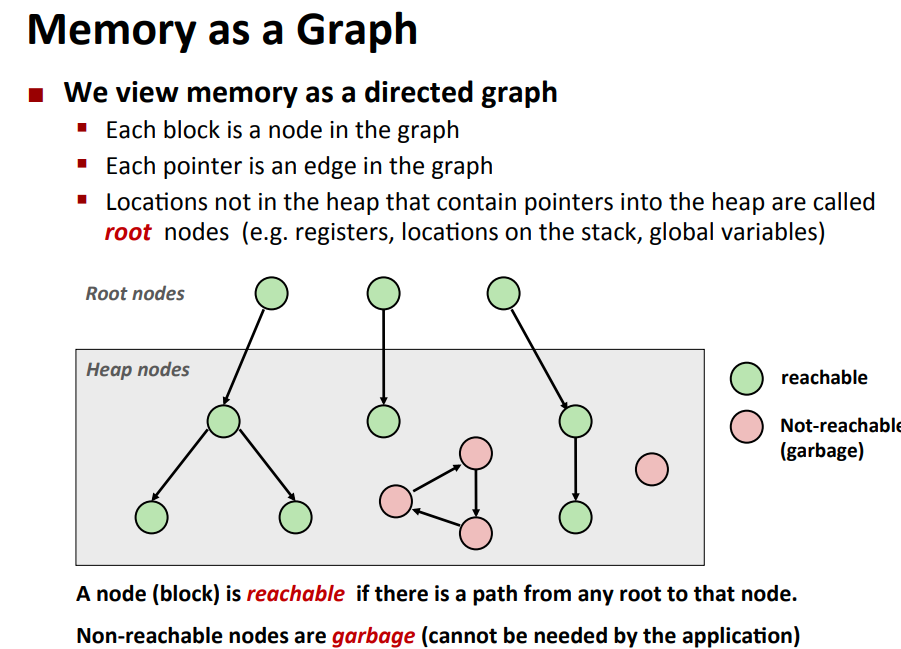
some assumption:
- when no pointer point to the object,it surely can be freed
- the collector must be able to distinguish the pointer and non-pointer
-
mark and sweep algorithm
- allocate until out of space
- use extra mark bit in the head of each block,start at root,traverse and mark all the node,then scan and delete non-marked node
-
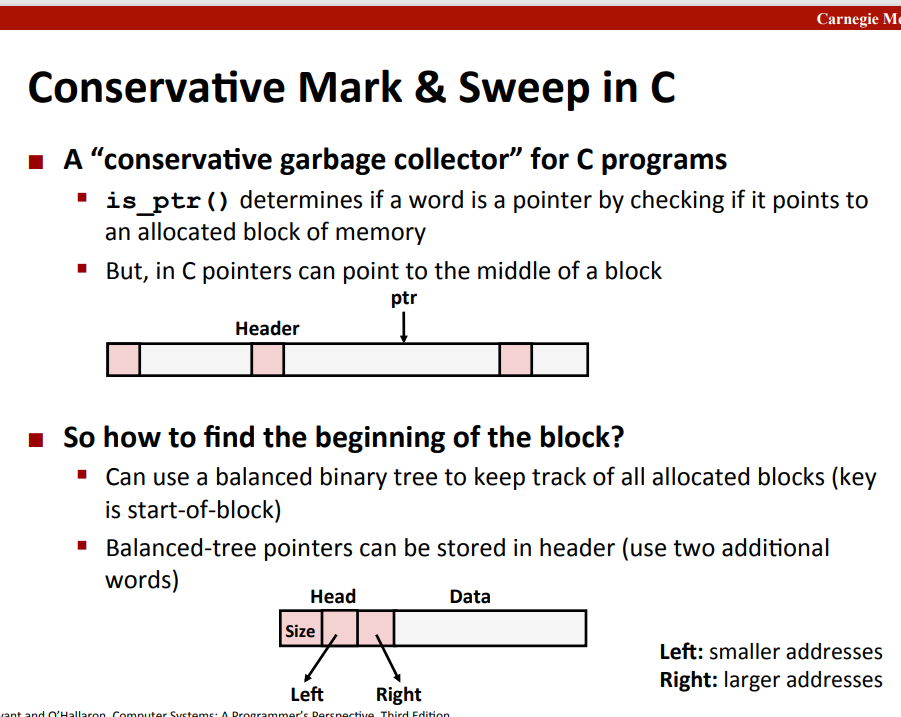
the conservative collector in C
-
complete understanding of C pointer(need to know the priority of operator(方括号和括号的优先级高于星))

-
deal with memory bug:
- gdb(debugger for simple)
- datastructure invarient consistency checker
- binary translator:valgrind
- glibc malloc contains checking code
malloc lab
- macro and inline:
macro:pre-compile time but no type checking and may have some side effect
inline_function:compile time do type checking - pointers:
pointer arithmetic is undefined on void* - idea
- 计算地址偏移量通常将指针转换为char*操作(这样以byte操作)
- 读写unsigned int*
- 堆中的指针默认是指向有效载荷的首地址
- 通常维护一个序言块和结尾块,哨兵的作用
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.


