东北大学《人工智能的数学基础》,笔者自学参考教材为
1.mathematics for machine learning
参考教材链接如下
mml-book
linear algebra(from book)
这部分参考MIT 线代和 3b1b笔记食用

general linear group(一般线性群):可逆矩阵关于矩阵乘法构成一般线性群,很明显这不是阿贝尔群
向量子空间:对于一个线性空间V,若 U∈V 且线性空间操作限制结果在U内,则U为一个向量子空间
生成集(generating set):对一个线性空间V,其所有向量都能由A中向量线性组合表示则A为V的生成集(基是最小的生成集)
AB=CCij=k∑aikbkjCkT=ABkTCi=AiB
基变换的神奇理解:
向量在某基向量下的坐标右乘上基向量矩阵得到的就是在标准基向量下的坐标
基变换是向量不变,表示变,线性变换是向量变,下列推导基变换矩阵
AxAxA=BxB=A−1BxB
线性映射
linear mapping:从一个空间映射到另一个空间
linear transformation:从一个空间映射回去
但是相当一部分情况下没有严格区分
线性映射同样具有单射(injective),双射(bijective),满射(surjective)
- 同构(Isomorphism):Φ:V←W 线性且双射
- 自同态(Endomorphism):Φ:V←V 线性
- 自同构(Automorphism):Φ:V←V 线性且双射
- 同态 (Homomorphism):先运算再映射等于先映射再运算
定理:有限维向量空间V和W同构当且仅当两者维度相同
- 为我们将 RM×N←RMN 提供了依据,因为存在一个双射,不会造成任何损失

Rank-Nullity Theorem:dim(ker(Phi))+dim(im(Phi))=dim(V)
affine spaces(仿射空间)


在n维空间中(n-1)维仿射子空间称为超平面(hyperplane)
y=x0+i=1∑n−1λibi
其中这n-1个线性无关的向量构成了一个子空间的基
当非齐次线性方程组有解的时候,其解空间就是一个仿射子空间
每个仿射映射都可以写为一个线性映射和位移的复合
analytic geometry(from book)
orthogonal projection
投影的严格定义:一个到其子空间的线性映射Pi,满足Pi的平方等于本身
投影的性质: 投影的结果是目标空间内与原向量最接近的( ∣∣x−π(x)∣∣ 最小) 投影结果一定是在目标空间内
- 向直线和一般子空间投影可以参考MIT 线代相关笔记
- 施密特正交化
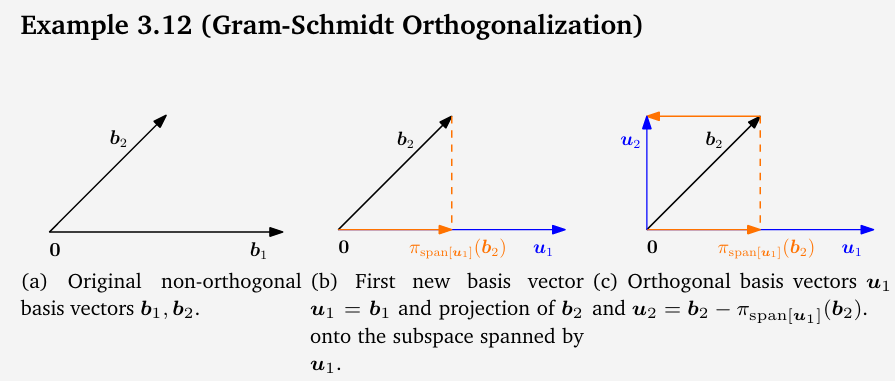
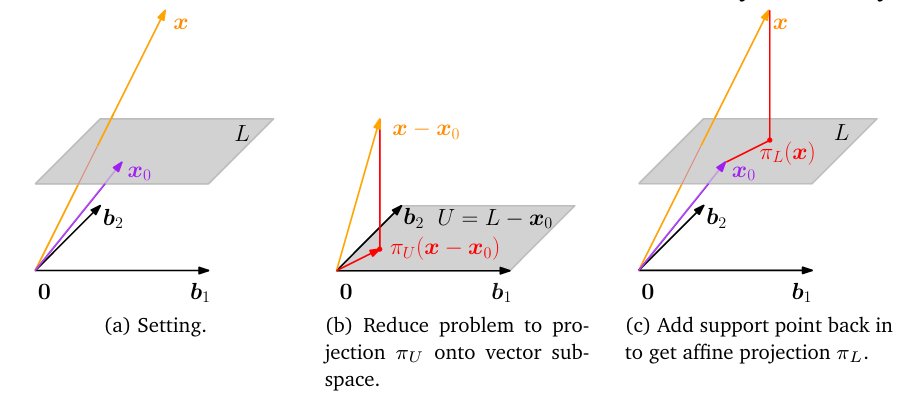
πL(x)=x0+πU(x−x0)
rotation
我们可以绕一条直线旋转一个平面
确定一个旋转的方法:找到标准基并使标准基旋转后的像互相正交
定义逆时针:从轴的正方向看向原点的方向看到的旋转
绕e1,e2,e3轴
1000cosθsinθ0−sinθcosθcosθ0−sinθ010sinθ0cosθcosθsinθ0−sinθcosθ0001
直觉上可以认为是固定n-2维,剩下两维在转
Givens rotation:设V为n维Euclidean vector space,the one automorphism satisfity

matrix decomposition(from book)
matrix approximation
由矩阵的SVD分解,一个秩为r的矩阵可以分解为r个秩为1的矩阵的加权和(大于r的奇异值为0)
A=i=1∑rσiuiviT=i=1∑rσiAi
如果我们不全部求和而是只求k个,这就得到了k阶近似矩阵A(k),其秩为k(都线性无关,也可以从矩阵乘法来看)
- norm
spectual norm of matrix(矩阵的谱范数)
∣∣A∣∣2:=xmax∣∣x∣∣2∣∣Ax∣∣2
矩阵的谱范数决定了任何向量经过矩阵能够变的最大长度
矩阵A的谱范数是其最大的奇异值
Eckart-young theorem:
A∈Rm∗n of rank r,let B∈Rm∗n of rank k,for any k≤r,A(k)=argminrk(B)=k∣∣A−B∣∣2
并且
∣∣A−A(k)∣∣2=σk+1
我们可以将这种近似理解为将原矩阵向至多k维的空间投影,所有投影中就范数而言的最小化
vector calculus(from book)
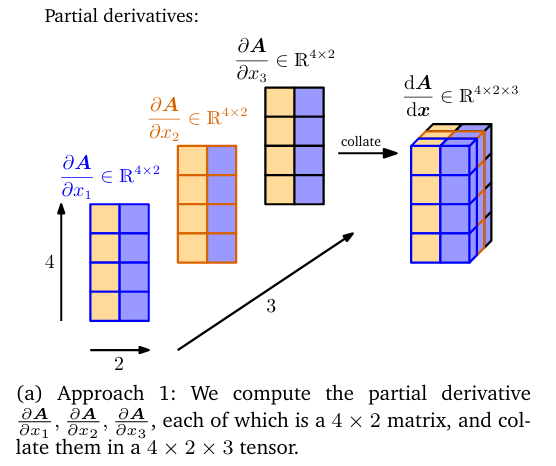
gradients of matrices
矩阵对矩阵的梯度是一个多维的张量(可以视为是array that collects partial derivatives)
A∈RM×N,B∈RP×Q,J∈R(M×N)×(P×Q)Ji,j,k,l=Bk,lAi,j
由于矩阵表示线性变换,我们可以构造从M*N到MN(矩阵到向量)的同构映射
两种计算方法(矩阵对向量求导)
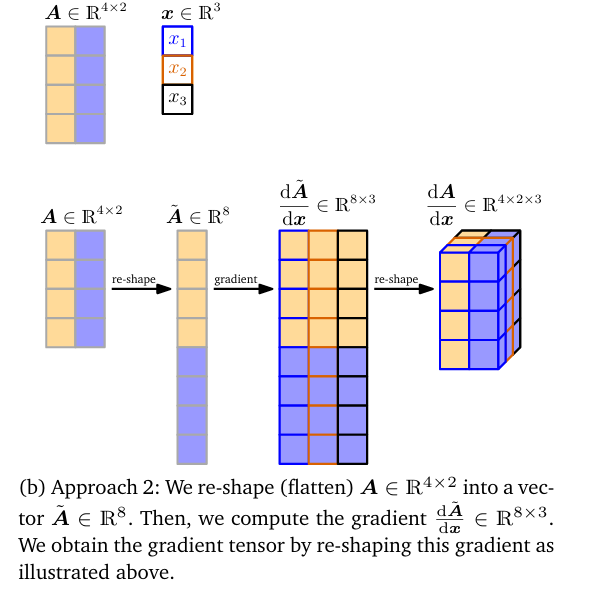
常用梯度恒等式
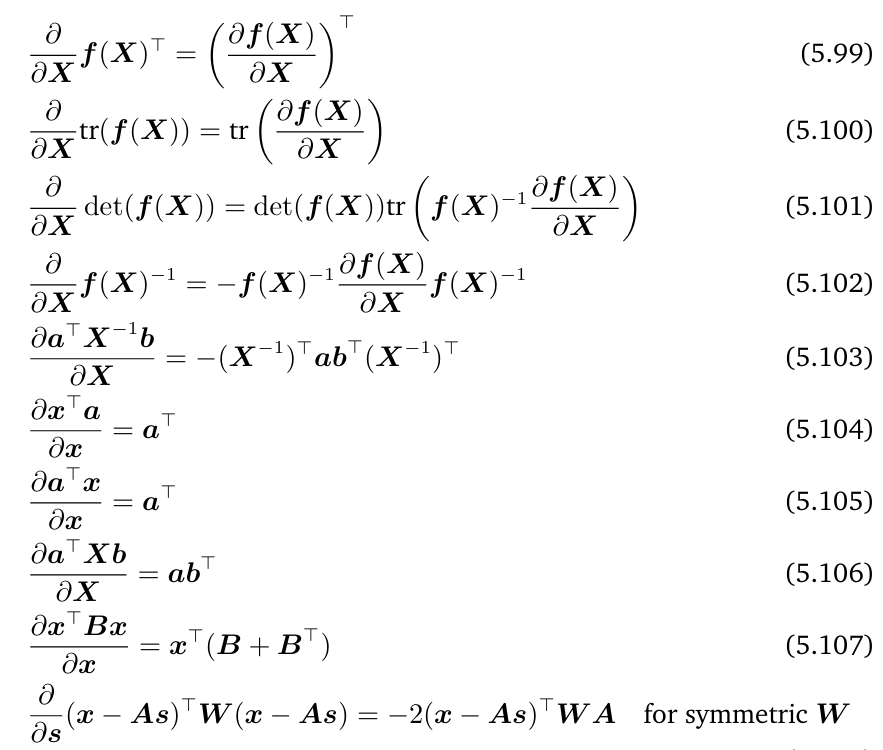
tip:在高阶张量中,通常意义的迹和转置是没有定义的
一个形状为 D×D××E×F 的张量的迹为 E×F的矩阵(tensor contraction的特殊情况)
类似的,我们的说的转置说的是交换前两个维度
backpropagation and automatic differentiation
-
反向传播
深度神经网络的反向传播,实际上可以极大的减少计算量
每一层参数的梯度实际上包含一个从损失到当前层输出的梯度的公共前缀
当我们开始计算对第i层参数的梯度,我们已经计算过L到i+1层输出的梯度,只需要计算跨层i+1到i的输出,本层梯度,结合前缀即可
-
自动微分
反向传播实际上是数值分析中的自动微分的一种特殊情况
可以视作一系列技巧计算梯度的数值(而不是符号解析形式),到机器精度上限
dxdy=(dbdydadb)dxdadxdy=dbdy(dadbdxda)
前者为反向传播,后者为正向传播,一般输出维度远小于输出维度,所以反向传播更便宜

linearization and multivariate Taylor series
对于从D维实数映射到实数的光滑函数
f(x)=i=0∑∞i!Dx(i)f(x0)(x−x0)i
其中D是k阶导数,上述的问题是当D大于1的时候,向量的k次方未被定义,实际上这一项和导数都是k阶张量
向量外积:
δ3[i,j,k]:=δ[i]δ[j]δ[k]
k=3时; np.einsum('ijk,i,j,k',df3,d,d,d)
爱因斯坦求和约定:
- 左边重复出现的维度:沿该维度乘积
- 左边出现而右边不出现:沿该维度求和
- 右边省略:取输入仅出现一次的索引
i=1∑Dj=1∑Dk=1∑DDx(3)f(x0)[i,j,k]δ[i]δ[j]δ[k]
probability and distribution(from book)
gaussian distribution
多元高斯分布
p(x∣μ,Σ)=(2π)d∣Σ∣1exp(−21(x−μ)TΣ−1(x−μ))
高斯分布的条件分布和边缘分布仍然是高斯分布
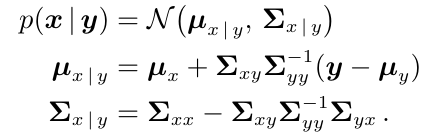
高斯分布的乘积是一个被常数因子缩放过的高斯分布


任何对于高斯随机变量的线性或仿射变换的结果也符合高斯分布
Conjugacy and the Exponential Family
一些对分布的期望属性:具有封闭性(closure property,应用规则返回的是相同类型的) 有更多数据时无需更多参数 参数估计表现良好
一种挺好的叫指数族分布(exponetial family):bernouli,binomial,beta
-
beta distribution
用于建模有限区间上的连续随机变量(0~1),常表示某些二元事件的概率

直觉上:alpha将概率质量往1拉,beta往0拉,两者小于1的时候有双峰,大于一的时候是单峰,若相等则对称
-
conjugacy:
若分布的先验和后验是同类型,则称该分布为关于该似然函数的共轭分布
常用证法:后验正比于先验乘似然
tips:注意区分一元和多元的先验是不同的,方差和精度的先验也不同(精度其实就是方差的导数)
-
sufficient statistics(充分统计量)
它包含了所有推断分布需要的信息(足以表示分布)

-
exponential family
P(x∣θ)=h(x)(exp(<θ,ϕ(x)>)−A(θ))
其中理论上可以是任何形式的内积,但是我们通常指定为普通的向量内积,A项保证积分或求和为1(log-partition function)
h(x)可以通过在内积中添加分量被吸收

P(x∣θ)=h(x)(exp(<θ,ϕ(x)>)−A(θ))p(θ∣γ)=hc(θ)(exp(<[γ1γ2],[θ−A(θ)]>−Ac(γ)))
e.g:(从伯努利推共轭为beta分布)
伯努利分布原本的形式是 p(x∣μ)=μx(1−μ)1−x。
通过取对数再接指数,改写为:
p(x∣μ)=exp[xlog(1−μμ)+log(1−μ)]
- 这里,自然参数 θ=log(1−μμ)(即对数几率 log-odds)。
- 归一化项(负的) −A(θ)=log(1−μ)。
根据前一页给出的通用模板 p(θ∣γ)∝exp(γ1θ−γ2A(θ)),作者定义了超参数 γ。
为了凑出我们熟悉的参数,作者设定 γ=[α,β+α]⊤。
带入后得到:
p(μ∣…)∝1−μμexp[αlog(1−μμ)+(β+α)log(1−μ)]
注:这里的 hc(μ)=1−μμ 是为了处理测度变换时的导数项,确保数学上的严谨性。
化简即可(hc选取完全可以全令为1,调整系数即可)
- 分布函数技术:就是概率论当中普通的通过计算变换后的CDF导出pdf
概率积分变换(probability integral transformation):CDF(F)严格单调的随机变量x,F(x)是均匀分布的随机变量

exercise
y=ax+b+w(x,w独立随机变量),p(y|x)和w一样的分布但是均值被平移(整体,从分布的变换来看)
独立->协方差为0
Cov(x,y)=E((x−E(x))(y−E(y))T)=E(xyT)−E(x)E(y)T
optimization(from book)
gadient descent
梯度下降法的收敛速度取决于矩阵的条件数(condition number)
κ(A)=∣∣A∣∣∣∣A−1∣∣
范数和逆的范数(诱导范数,就是最大奇异值)分别衡量了矩阵A拉伸和压缩向量的能力
推导可得
κ(A)1∣∣b∣∣∣∣δb∣∣≤∣∣x∣∣∣∣δx∣∣≤κ(A)∣∣b∣∣∣∣δb∣∣
Constrained Optimization and Lagrange Multipliers
origin problem:
minxf(x)subject to gi(x)≤0,for all i 1,2...
Lagrangian:
L(x,λ)=f(x)+i=1∑mλigi(x)=f(x)+λ⊤g(x)
对偶问题

minimax inequality
maxyminxϕ(x,y)≤minxmaxyϕ(x,y)
L关于lambda是仿射函数,一系列仿射函数的pointwise minimum(一系列函数在某点的最小值)必然导致凹性
convex optimization
epigraph:对一个凸函数,每个自变量对应横坐标处大于函数值的所有点,集合称为epigraph(是凸集)
一组凸函数的非负加权和仍然保持凸性
凸优化:目标函数和不等式函数全部是凸函数,等式约束对应的也是凸集
-
linear programming
原问题: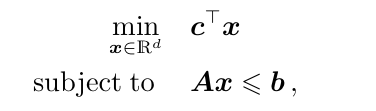
对偶: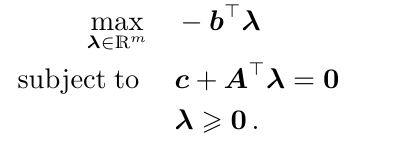
-
quadratic programming(二次规划)
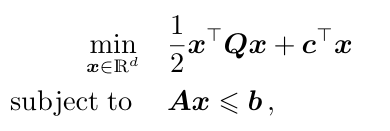
-
Legendre–Fenchel Transform and Convex Conjugate
凸集可以由其支持超平面表示
支持超平面(support hyperplane):与该凸集相交并且凸集仅位于超平面的一侧
可以fill 凸函数来获得凸集,所以也可以用支持超平面(相切,就是梯度)描述凸函数
convex conjugate(转换视角,通过每点的切线斜率和截距描述)
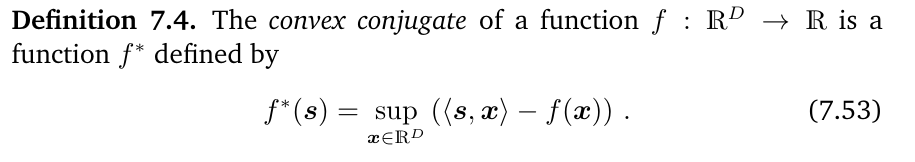
注意:此处并未要求函数是凸函数或者可导
其本质就是该处切线截距的负值
-
凸共轭的性质:
- 凸共轭一定是凸函数,无论原函数是什么样子
- 对凸共轭求凸共轭得到原本的函数
- 原函数f(x)的斜率为s,凸共轭f(s)的斜率为x



