
无监督域自适应模型压缩的迭代知识提取和剪枝
文献阅读记录
地址:Iterative knowledge distillation and pruning for model compression in unsupervised domain adaptation
abstract
深度学习实际应用中的两个问题:训练数据与测试数据分布不一致,不充足的标签数据
无监督域适应学习(unsupervised domain adaptaion,UDA),是解决这一问题的重要技术
现有UDA难以满足实时推理和资源受限场景的要求,模型压缩则会降低表现
提出方法ITMC(iterative transfer model compression):交替执行TKD(transfer knowledge distillation),和ACP(adaptive channel pruning)
- 论文贡献:
提出ITMC,迭代式进行蒸馏和剪枝
TKD和ACP,动态剪枝.
related work
UDA(Unsupervised Domain Adaptation)
UDA是用来解决训练集和测试集的数据分布迁移导致的性能下降的,通常我们的测试集较难获取大量标签数据,而源域(source domain)有标签
核心思想:特征对齐(feature alignment)
- 基于样本的 UDA (Sample-based UDA)
核心逻辑: 寻找跨领域中具有“相似分布”的样本。
关键点: 它的重点在于筛选或加权。从源域中找出那些在特征上与目标域数据非常接近的样本,并利用这些高质量样本来辅助目标域的模型训练。
主要挑战: 如何在没有标签的情况下,精准地识别出两域之间分布相似的样本并高效利用它们。 - 基于映射的 UDA (Mapping-based UDA)
核心逻辑: 学习一个映射函数,将源域和目标域的数据投影到同一个共享特征空间。
关键点: 只要在这个共享空间里,不同领域的数据看起来“长得差不多”(特征表示相似),模型在源域学到的知识就能泛化到目标域。
常用度量工具:
MMD (最大均值差异): 衡量两个分布在空间中的均值距离。
CORAL (相关性对齐): 衡量并对齐两个分布的二阶统计量(协方差)。 - 基于对抗的 UDA (Adversarial-based UDA)
核心逻辑: 通过“博弈”训练来消除领域差异。
三个关键组件及其分工:
特征提取器 (Feature Extractor): 负责从源域和目标域中提取特征。
领域判别器 (Domain Discriminator): 负责判断提取出的特征到底是来自源域还是目标域。它的目标是尽可能减小领域对抗损失(即让判别器分不清来源)。
类别预测器 (Class Predictor): 负责确保模型在源域上的分类准确性(因为源域有标签)。
训练过程: 特征提取器努力“欺骗”判别器,让判别器无法分辨领域;而判别器努力“拆穿”提取器。通过这种协同训练,最终提取出领域无关(Domain-invariant)的鲁棒特征。
method
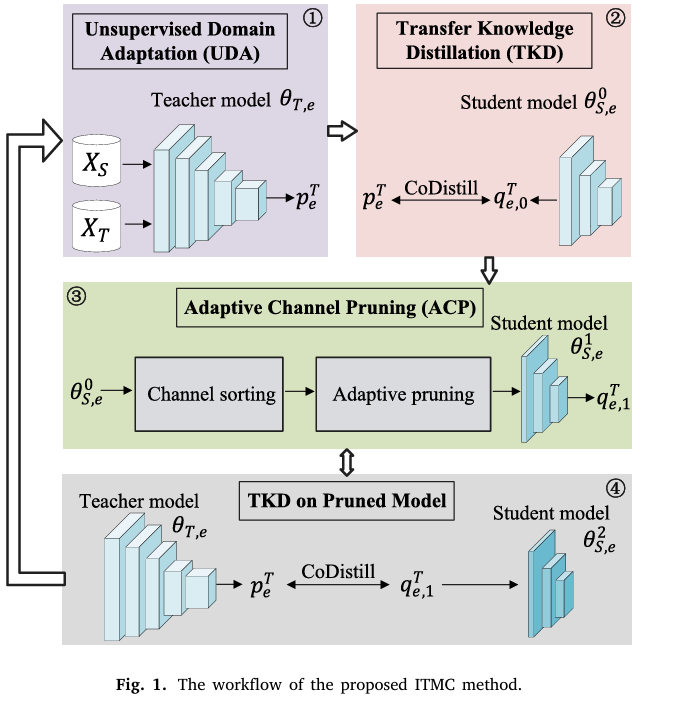
TKD
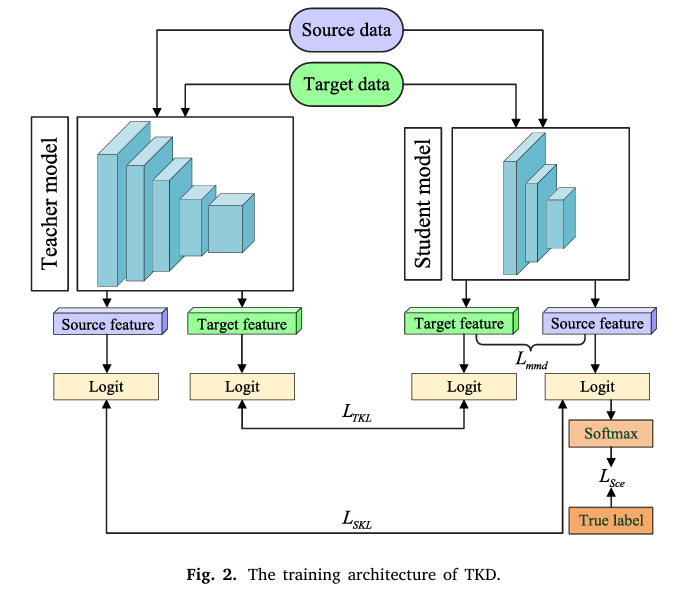
- 教师模型在UDA任务中的训练
其中phi为特征映射函数,映射至RKHS,c表示类别
- 学生模型
其中T为温度参数,通常大于一,LS为学生模型总损失函数,LSCE为学生模型在源域上的交叉熵,beta是逐渐增大至1的参数
ACP
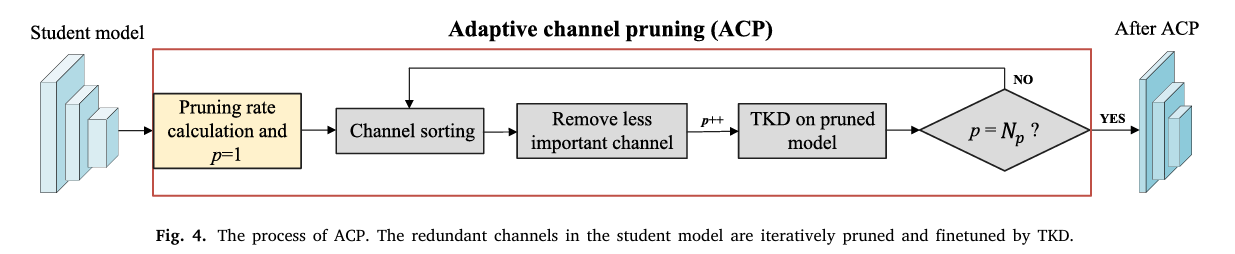
- channel sorting criterion
比较剪枝前后结果的变化,直觉上变化更大的更重要
直接比较是否计算某个通道的变化计算量极大,此处使用一阶泰勒近似
其中as表示source domain中的激活值(梯度乘激活值意味着影响力乘信息量)
动态剪枝率
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.


