cs149 part one | Word Count: 2.2k | Reading Time: 9mins
Why Parallelism? Why Efficiency?
observation:
communication limits the maximun speedup of parallel
imbalance of work load limits the speedup
communication can be the domain limits
历史上cpu性能提升极快,并行没那么有用
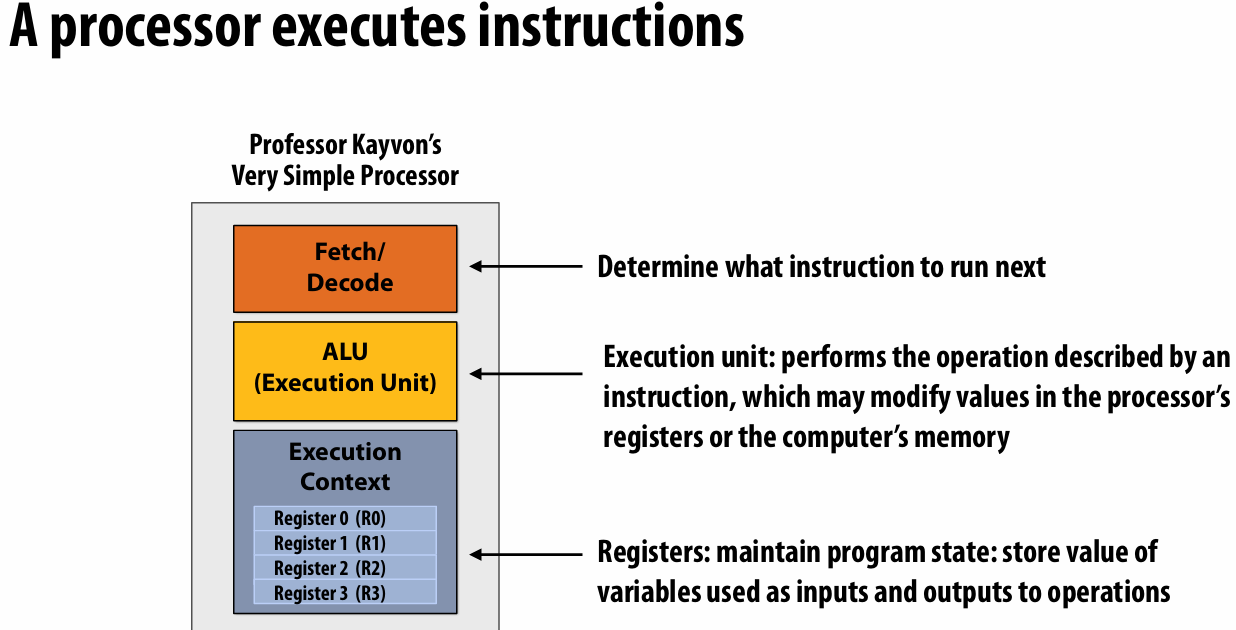
计算机视角:程序只是一段指令序列
superscalar processor execution
instruction level parallelism(ILP)
memory:just an array of bytes(dram这些是具体的implementation)
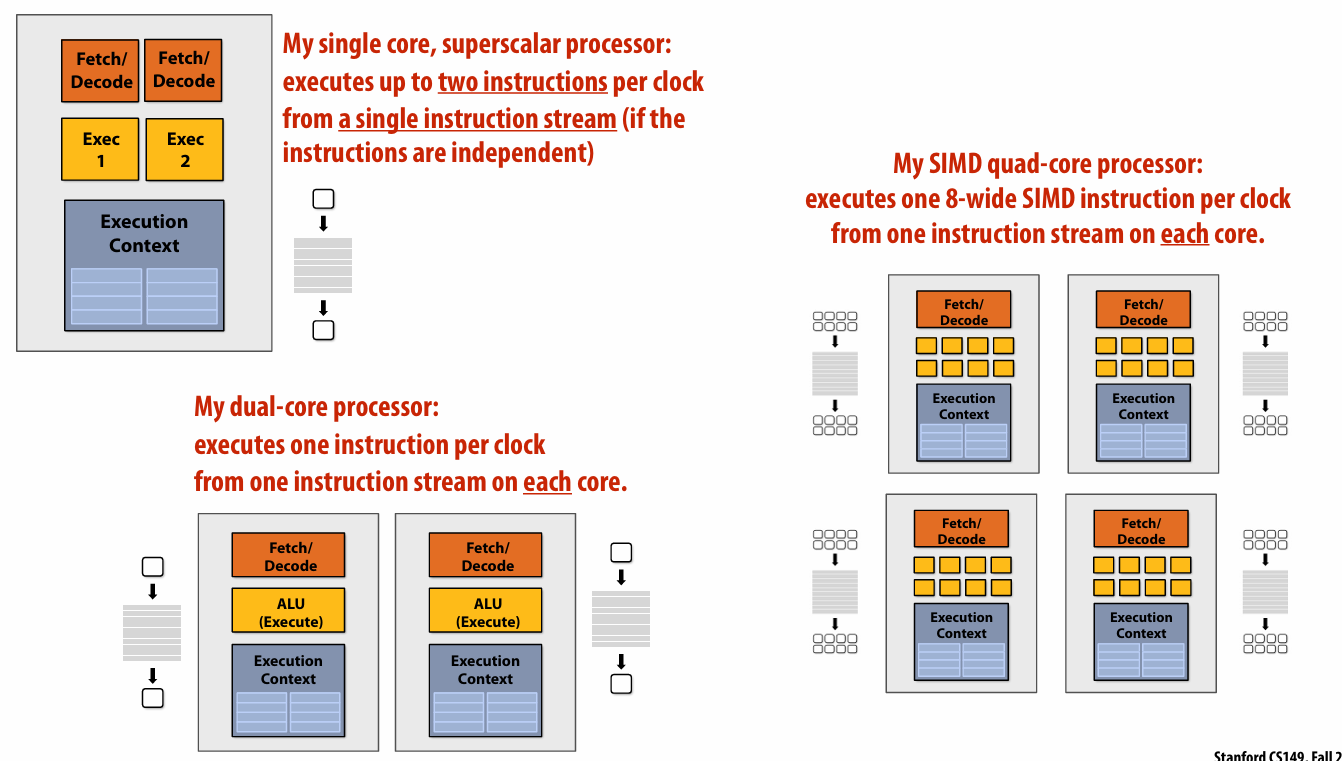
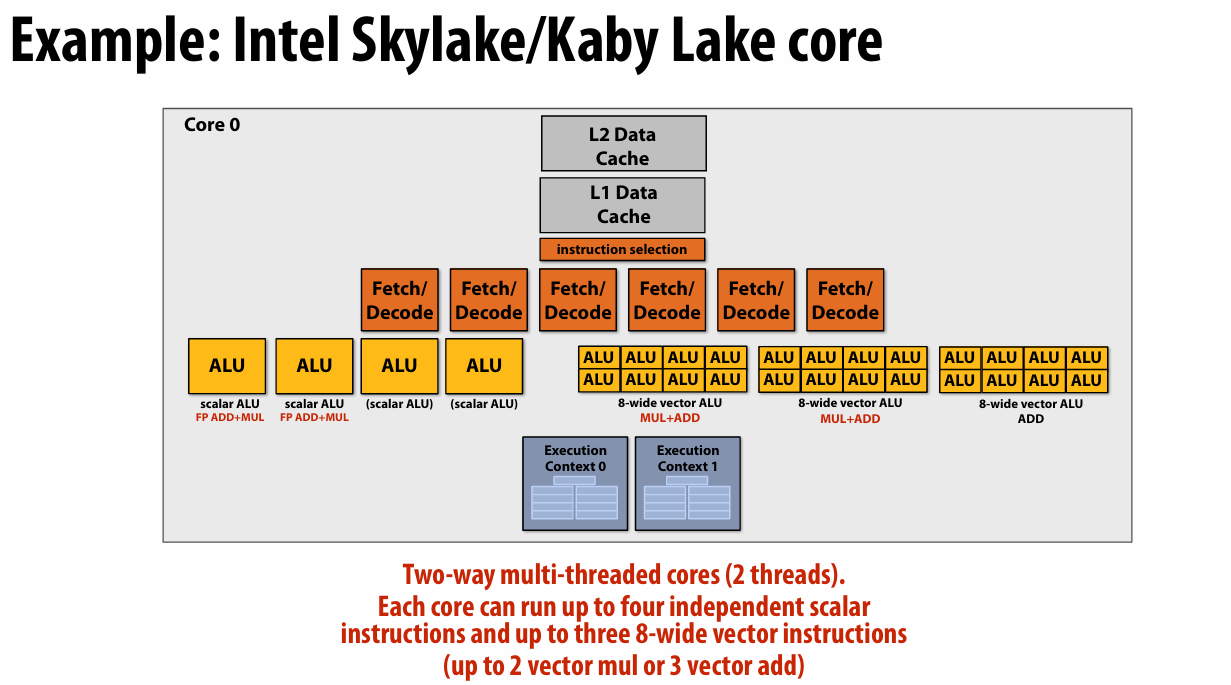
A Modern Multi-Core Processor (Part I)
示例:利用泰勒近似计算数组中每个值的sin 函数值
for (int i = 0 ; i < n; i++) { y[i] = sin (x[i]); }
内部的并行性是有限的,但是每个循环所操作的值完全不同,这种复杂的并行性很难被超标量处理器做到
1.多核处理器
2.单指令多数据(SIMD)
3.多进程与上下文切换
Multi-core Arch Part II + ISPC Programming Abstractions
memory bandwidth:the rate at which memory can provide data to processor
abstraction vs implementation
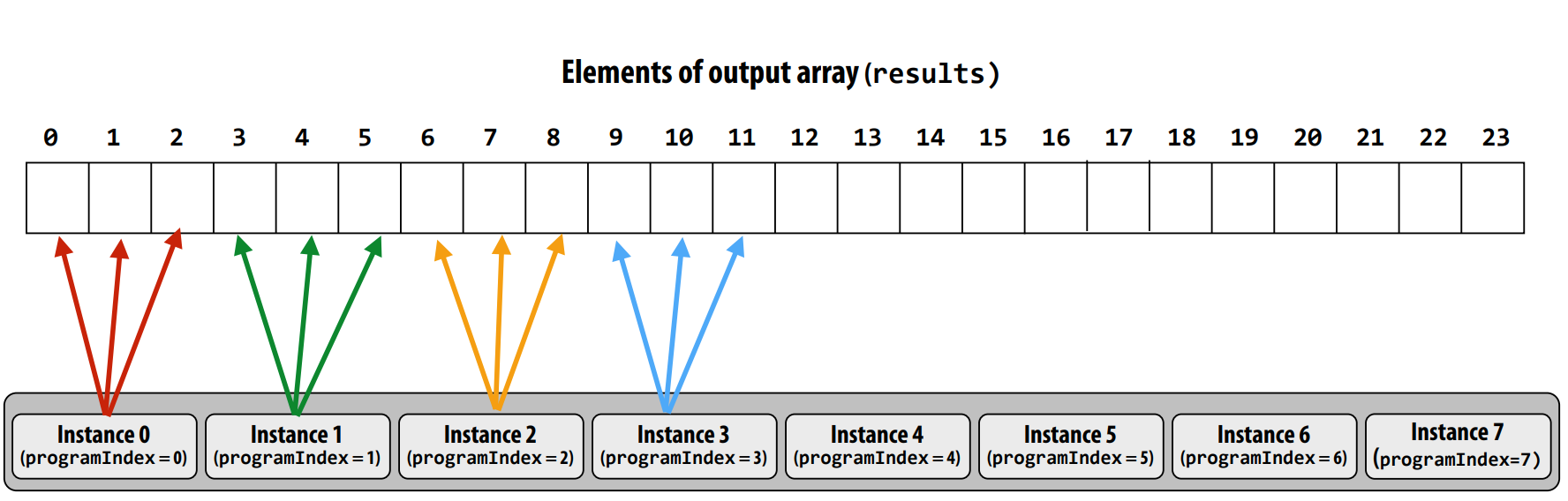
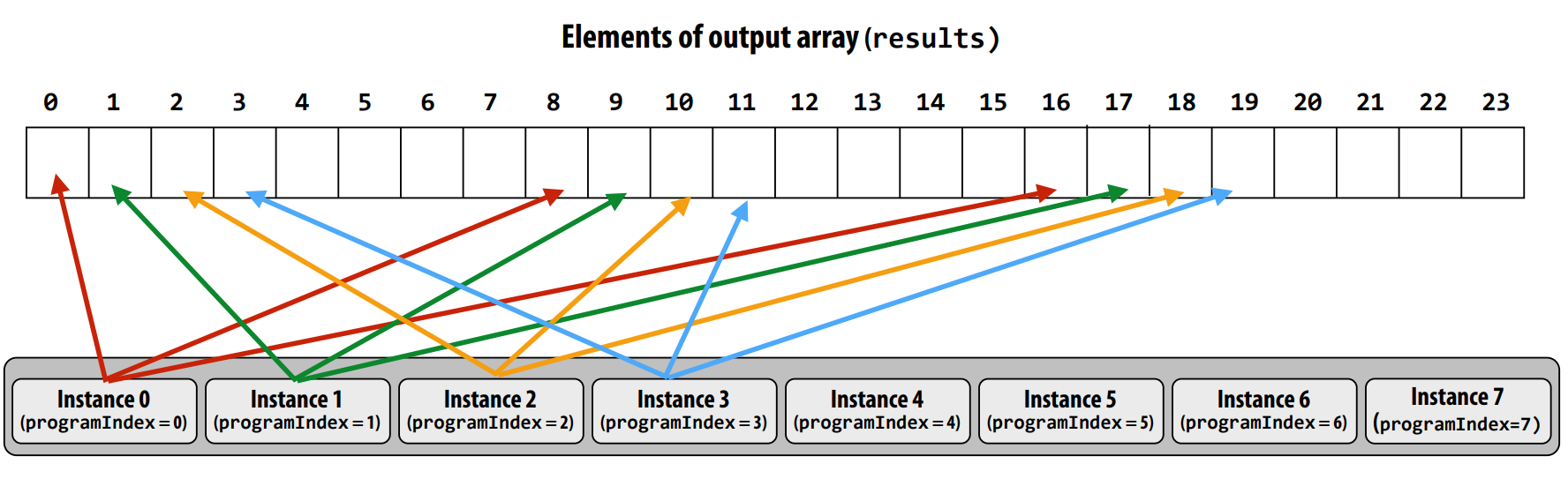
ISPC:Intel SIMD programming compiler
PA1
prog1
gdb:编译的时候使用-g开启调试
spatial decompositon:将任务分解为空间中相邻的算法
void workerThreadStart (WorkerArgs * const args) double t_startTime = CycleTimer::currentSeconds (); const unsigned int CHUNK_SIZE = 16 ; for (unsigned int cur_row = args->threadId * CHUNK_SIZE; cur_row < args->height; cur_row += args->numThreads * CHUNK_SIZE) { int numRows = std::min (CHUNK_SIZE, args->height - cur_row); mandelbrotSerial (args->x0, args->y0, args->x1, args->y1, args->width, args->height, cur_row, numRows, args->maxIterations, args->output); } double t_endTime = CycleTimer::currentSeconds (); printf ("Thread %d: [%.3f] ms\n" , args->threadId, (t_endTime - t_startTime) * 1000 ); }
prog2
void recurssive_while (__cs149_vec_int& count,__cs149_vec_float&result,__cs149_vec_float&input,__cs149_mask&NotExpZero) _cs149_vgt_int(NotExpZero,count,IntZero,NotExpZero); if (_cs149_cntbits(NotExpZero)==0 )return ; _cs149_vmult_float(result,result,input,NotExpZero); _cs149_vsub_int(count,count,IntOne,NotExpZero); recurssive_while (count,result,input,NotExpZero); } void clampedExpVector (float * values, int * exponents, float * output, int N) __cs149_mask IsExpZero; __cs149_mask NotExpZero; __cs149_vec_int exp; __cs149_vec_float val; __cs149_mask IsOver; for (int i=0 ;i<N;i+=VECTOR_WIDTH){ __cs149_mask Init; int pos=i; Init=_cs149_init_ones(min (VECTOR_WIDTH,N-i)); _cs149_vload_float(val,values+pos,Init); _cs149_vload_int(exp,exponents+pos,Init); _cs149_vset_float(ret,1.f ,Init); _cs149_vlt_int(IsExpZero,exp,IntOne,Init); NotExpZero =_cs149_mask_not(IsExpZero); _cs149_vmove_float(ret,val,NotExpZero); __cs149_vec_int count; _cs149_vsub_int(count,exp,IntOne,NotExpZero); recurssive_while (count,ret,val,NotExpZero); _cs149_vgt_float(IsOver,ret,upper,Init); _cs149_vset_float(ret,9.999999f ,IsOver); _cs149_vstore_float(output+pos,ret,Init); } }
prog3
//export:表示该ispc函数是被c/cpp调用的 //uniform:表示该变量在所有的program instances保持不变(从c传出来的参数必须uniform) //数组参数和c一样,会被转化为指向第一个元素的指针 //foreach:是通过声明利用SIMD export void mandelbrot_ispc(uniform float x0, uniform float y0, uniform float x1, uniform float y1, uniform int width, uniform int height, uniform int maxIterations, uniform int output[]) { float dx=(x1-x0)/width; float dy=(y1-y0)/height; for(uniform int j=0;j<height;j++){ foreach(i=0...width){ float x = x0 + i * dx; float y = y0 + j * dy; int index = j * width + i; output[index] = mandel(x, y, maxIterations); } } } //ISPC利用多线程的机制是launch task export void mandelbrot_ispc_withtasks(uniform float x0, uniform float y0, uniform float x1, uniform float y1, uniform int width, uniform int height, uniform int maxIterations, uniform int output[]) { uniform int rowsPerTask = height / 16; // create 2 tasks launch[16] mandelbrot_ispc_task(x0, y0, x1, y1, width, height, rowsPerTask, maxIterations, output); }
区分task and multithread:
prog4
最大化加速比:
减少随机性,让每个数据的计算量接近,SIMD跑满
大量计算量,可以掩盖多进程和内存读写的开销
有些时候可能存在"拔河":改变参数同时导致不同数据计算量不同的同时增大了计算量(看哪边更明显)
最小化的情景:
计算开销相对而言远小于内存搬运
对SIMD而言,严重的条件分支可能导致空转
AVX(是指令集,常用的是AVX intrinsinc):
load和store最好unaligned(你申请的内存不一定32位等对齐了)zhihu
void sqrtAVX (int N, float initialGuess, float *values, float *output) if (!values || !output || N <= 0 ) return ; static const float kThreshold = 0.00001f ; int aligned_n = (N / 8 ) * 8 ; for (int i = 0 ; i < aligned_n; i += 8 ) { __m256 threshold = _mm256_set1_ps(kThreshold); __m256 x_vec = _mm256_loadu_ps(&values[i]); __m256 guess = _mm256_set1_ps(initialGuess); __m256 pred = _mm256_sub_ps( _mm256_mul_ps(_mm256_mul_ps(guess, guess), x_vec), _mm256_set1_ps(1.0f ) ); pred = _mm256_andnot_ps(_mm256_set1_ps(-0.0f ), pred); while (_mm256_movemask_ps(_mm256_cmp_ps(pred, threshold, _CMP_GT_OQ)) != 0 ) { guess = _mm256_mul_ps( _mm256_set1_ps(0.5f ), _mm256_sub_ps( _mm256_mul_ps(_mm256_set1_ps(3.0f ), guess), _mm256_mul_ps(x_vec, _mm256_mul_ps(guess, _mm256_mul_ps(guess, guess))) ) ); pred = _mm256_sub_ps( _mm256_mul_ps(_mm256_mul_ps(guess, guess), x_vec), _mm256_set1_ps(1.0f ) ); pred = _mm256_andnot_ps(_mm256_set1_ps(-0.0f ), pred); } _mm256_storeu_ps(&output[i], _mm256_mul_ps(x_vec, guess)); } for (int i = aligned_n; i < N; i++) { float x = values[i]; float guess = initialGuess; float error = fabs (guess * guess * x - 1.f ); while (error > kThreshold) { guess = (3.f * guess - x * guess * guess * guess) * 0.5f ; error = fabs (guess * guess * x - 1.f ); } output[i] = x * guess; } }
prog5&6
读写瓶颈:写入的时候先读入缓存行再写,再存回去,这样很耗时间,一种方法是直接写回主存
for (int i=0 ;i<THREAD_NUMBER;i++){ woker[i]=std::thread (computeAssignments,&arg[i]); } for (int i=0 ;i<THREAD_NUMBER;i++){ if (woker[i].joinable ()) woker[i].join (); }