参考自英伟达官方教程 link zhihu
CUDA Made Easy
execution space
execution space:where the code execute
#include <thrust/execution_policy.h> #include <thrust/universal_vector.h> #include <thrust/transform.h> #include <cstdio> int main () float k = 0.5 ; float ambient_temp = 20 ; thrust::universal_vector<float > temp{ 42 , 24 , 50 }; auto transformation = [=] __host__ __device__ (float temp) { return temp + k * (ambient_temp - temp); }; std::printf ("step temp[0] temp[1] temp[2]\n" ); for (int step = 0 ; step < 3 ; step++) { thrust::transform (thrust::device, temp.begin (), temp.end (), temp.begin (), transformation); std::printf ("%d %.2f %.2f %.2f\n" , step, temp[0 ], temp[1 ], temp[2 ]); } }
两个要点:函数定义前的修饰符得要对,执行的时候传进去的设备参数也得对
Extending Standard Algorithms
example
正确但低效的代码
#include "ach.h" float naive_max_change (const thrust::universal_vector<float >& a, const thrust::universal_vector<float >& b) thrust::universal_vector<float > unnecessarily_materialized_diff (a.size()) ; thrust::transform (thrust::device, a.begin (), a.end (), b.begin (), unnecessarily_materialized_diff.begin (), []__host__ __device__(float x, float y) { return abs (x - y); }); return thrust::reduce (thrust::device, unnecessarily_materialized_diff.begin (), unnecessarily_materialized_diff.end (), 0.0f , thrust::maximum<float >{}); } int main () float k = 0.5 ; float ambient_temp = 20 ; thrust::universal_vector<float > temp[] = {{ 42 , 24 , 50 }, { 0 , 0 , 0 }}; auto transformation = [=] __host__ __device__ (float temp) { return temp + k * (ambient_temp - temp); }; std::printf ("step max-change\n" ); for (int step = 0 ; step < 3 ; step++) { thrust::universal_vector<float > ¤t = temp[step % 2 ]; thrust::universal_vector<float > &next = temp[(step + 1 ) % 2 ]; thrust::transform (thrust::device, current.begin (), current.end (), next.begin (), transformation); std::printf ("%d %.2f\n" , step, naive_max_change (current, next)); } }
iterator
使用迭代器可以认为就是使用指针的泛化
#include "ach.h" struct wrapper { int *ptr; void operator =(int value) { *ptr = value / 2 ; } }; struct transform_output_iterator { int *a; wrapper operator [](int i) { return {a + i}; } }; int main () std::array<int , 3> a{ 0 , 1 , 2 }; transform_output_iterator it{a.data ()}; it[0 ] = 10 ; it[1 ] = 20 ; std::printf ("a[0]: %d\n" , a[0 ]); std::printf ("a[1]: %d\n" , a[1 ]); }
cuda iterator
#include "ach.h" float max_change (const thrust::universal_vector<float >& a, const thrust::universal_vector<float >& b) auto zip = thrust::make_zip_iterator (a.begin (), b.begin ()); auto transform = thrust::make_transform_iterator (zip, []__host__ __device__(thrust::tuple<float , float > t) { return abs (thrust::get <0 >(t) - thrust::get <1 >(t)); }); return thrust::reduce (thrust::device, transform, transform + a.size (), 0.0f , thrust::maximum<float >{}); } int main () float k = 0.5 ; float ambient_temp = 20 ; thrust::universal_vector<float > temp[] = {{ 42 , 24 , 50 }, { 0 , 0 , 0 }}; auto transformation = [=] __host__ __device__ (float temp) { return temp + k * (ambient_temp - temp); }; std::printf ("step max-change\n" ); for (int step = 0 ; step < 3 ; step++) { thrust::universal_vector<float > ¤t = temp[step % 2 ]; thrust::universal_vector<float > &next = temp[(step + 1 ) % 2 ]; thrust::transform (thrust::device, current.begin (), current.end (), next.begin (), transformation); std::printf ("%d %.2f\n" , step, max_change (current, next)); } }
cpp lambda
三种方法传递可调用对象:function pointer,functor(仿函数),lambda[ capture-list ] ( params ) mutable(optional) exception(optional) attribute(optional) -> ret(optional) { body } [target]:按值捕获 [&target]:按引用捕获 [v = target]:按值捕获target,函数内部叫v[=] or [&]按值或引用捕获可见范围内所有的局部变量int C::func() const{},不会修改成员变量
Vocabulary Types
thrust::tabulate对数组每个下标处执行operator然后存在原来的位置(map)cuda::std::mdspan可处理任意维度的坐标
#include <cuda/std/mdspan> #include <cuda/std/array> #include <cstdio> cuda::std::mdspan temp_in (thrust::raw_pointer_cast(in.data()), height, width) ; thrust::tabulate (thrust::device, out.begin (), out.end (), [temp_in] __host__ __device__(int id) { int column = id % temp_in.extent (1 ); int row = id / temp_in.extent (1 ); if (row > 0 && column > 0 && row < temp_in.extent (0 ) - 1 && column < temp_in.extent (1 ) - 1 ) { float d2tdx2 = temp_in (row, column - 1 ) - 2 * temp_in (row, column) + temp_in (row, column + 1 ); float d2tdy2 = temp_in (row - 1 , column) - 2 * temp_in (row, column) + temp_in (row + 1 , column); return temp_in (row, column) + 0.2f * (d2tdx2 + d2tdy2); } else { return temp_in (row, column); } });
Serial vs Parallel
for loop是完全的串行的,非常慢thrust::reduce_by_key reduce segments of values
#include <thrust/iterator/counting_iterator.h> #include <thrust/iterator/transform_iterator.h> #include <thrust/iterator/discard_iterator.h> #include <thrust/reduce.h> #include <thrust/execution_policy.h> thrust::universal_vector<float > row_temperatures ( int height, int width, thrust::universal_vector<int >& row_ids, thrust::universal_vector<float >& temp) thrust::universal_vector<float > sums (height) ; auto row_indices_gen = thrust::make_transform_iterator ( thrust::make_counting_iterator (0 ), [=] __host__ __device__ (int i) { return i / width; } ); thrust::reduce_by_key (thrust::device, row_indices_gen, row_indices_gen + temp.size (), temp.begin (), thrust::make_discard_iterator (), sums.begin ()); return sums; } struct mean_functor { int width; __host__ __device__ float operator () (float x) const { return x / width; } }; auto means_output = thrust::make_transform_output_iterator ( means.begin (), mean_functor{width});
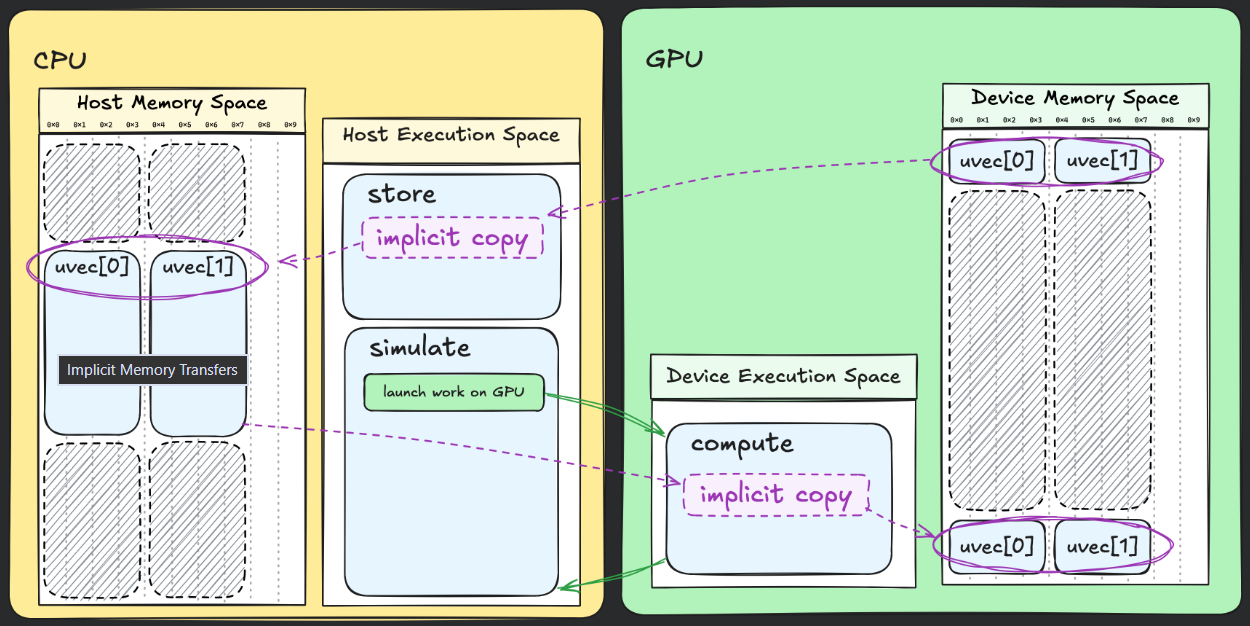
memory spaces
thrust::universal_vector同时在cpu和gpu的memory space并且有automatic migratesthrust::host_vector/thrust::device_vector
在host code中取address of device function is not allowed
Unlocking the GPU’s Full Potential
Asynchrony
thrust在cpu和gpu之间是同步的(cpu 的thrust launch了gpu task后是空闲的)cudaDeviceSynchronize():让cpu等gpu完成
nsight:tool for profile your program
为了方便看,可以在代码中使用NVTXnvtx3::scoped_range temp{std::string("copy stage")}//建立一个range,直接放在一个{}块里面就可以标记成功
streams
为了更好的重叠操作以提高性能,需要异步的内存复制
#include "ach.h" int main () int height = 2048 ; int width = 8192 ; cudaStream_t compute_stream; cudaStreamCreate (&compute_stream); cudaStream_t copy_stream; cudaStreamCreate (©_stream); thrust::device_vector<float > d_prev = ach::init (height, width); thrust::device_vector<float > d_next (height * width) ; thrust::device_vector<float > d_buffer (height * width) ; thrust::host_vector<float > h_prev (height * width) ; const int compute_steps = 750 ; const int write_steps = 3 ; for (int write_step = 0 ; write_step < write_steps; write_step++) { cudaMemcpy (thrust::raw_pointer_cast (d_buffer.data ()), thrust::raw_pointer_cast (d_prev.data ()), height * width * sizeof (float ), cudaMemcpyDeviceToDevice); cudaMemcpyAsync (thrust::raw_pointer_cast (h_prev.data ()), thrust::raw_pointer_cast (d_buffer.data ()), height * width * sizeof (float ), cudaMemcpyDeviceToHost, copy_stream); for (int compute_step = 0 ; compute_step < compute_steps; compute_step++) { ach::simulate (width, height, d_prev, d_next, compute_stream); d_prev.swap (d_next); } cudaStreamSynchronize (copy_stream); ach::store (write_step, height, width, h_prev); cudaStreamSynchronize (compute_stream); } cudaStreamDestroy (compute_stream); cudaStreamDestroy (copy_stream); }
pinned memory
直接使用上述方法仍然可能无法同步:thrust::universal_host_pinned_vector声明buffer即可
Implementing New Algorithms
kernels
一个使用__global__修饰的函数叫kernel:invoked on cpu but run on gpukernel<<<1,1,0,stream>>>()gridDim.x blockDim.x blockIdx.x threadIdx.x 前两个参数是gridsize和blocksizecuda::ceil_div(width, block_size)
histogram&sync
计算数据统计的histogram图的时候会出现data race,要用原子操作cuda::std::atomic_ref_syncthreads()同步线程cuda::std::atomic_ref<int> cuda::atomic_ref<int,cuda::thread_scope_system>
shared&cooperative
shared memory:不存在global memory中,而是直接放在一个块的共享内存,跑得更快
__shared__ int block_histogram[num_bins]; if (threadIdx.x < num_bins) { block_histogram[threadIdx.x] = 0 ; } __syncthreads(); int cell = blockIdx.x * blockDim.x + threadIdx.x;int bin = static_cast <int >(temperatures[cell] / bin_width);cuda::atomic_ref<int , cuda::thread_scope_block> block_ref (block_histogram[bin]) ;block_ref.fetch_add (1 , cuda::memory_order_relaxed); __syncthreads(); if (threadIdx.x < num_bins) { cuda::atomic_ref<int , cuda::thread_scope_device> ref (histogram[threadIdx.x]) ; ref.fetch_add (block_histogram[threadIdx.x], cuda::memory_order_relaxed); }
sequential algorithm:invoked and executed by a single thread
cooperative algorithm:invoked and executed by multi threads
parallel algorithm:invoked by a single thread but run internally on multiple threads
#include "ach.cuh" constexpr int block_size = 256 ;constexpr int items_per_thread = 1 ;constexpr int num_bins = 10 ;constexpr float bin_width = 10 ;__global__ void histogram_kernel (cuda::std::span<float > temperatures, cuda::std::span<int > histogram) __shared__ int block_histogram[num_bins]; int cell = blockIdx.x * blockDim.x + threadIdx.x; int bins[items_per_thread] = { static_cast <int >(temperatures[cell] / bin_width)}; using histogram_t = cub::BlockHistogram<int , block_size, items_per_thread, num_bins, cub::BlockHistogramAlgorithm::BLOCK_HISTO_ATOMIC>; __shared__ typename histogram_t ::TempStorage temp_storage; histogram_t (temp_storage).Histogram (bins, block_histogram); __syncthreads(); if (threadIdx.x < num_bins) { cuda::atomic_ref<int , cuda::thread_scope_device> ref ( histogram[threadIdx.x]) ref.fetch_add (block_histogram[threadIdx.x]); } } void histogram (cuda::std::span<float > temperatures, cuda::std::span<int > histogram, cudaStream_t stream) int grid_size = cuda::ceil_div (temperatures.size (), block_size); histogram_kernel<<<grid_size, block_size, 0 , stream>>>(temperatures, histogram); }