origin targets:rendering 3D image
使用三角形描述,给定图片各点的材料,camera,计算投影的样子
early scientiffic computation:
指定区域,fragment shader function 换成实际要执行的函数
2007之前:gpu只有计算graphics pipeline 的interface
2007之后的架构:
Let’s say a user wants to run a non-graphics program on the GPU’s
programmable cores…
Application can allocate buffers in GPU memory and copy data
to/from buffers
Application (via graphics driver) provides GPU a single kernel
program binary
Application tells GPU to run the kernel in an SPMD fashion
(“run N instances of this kernel”)
launch(myKernel, N)
CUDA abstraction
programming model:SPMD
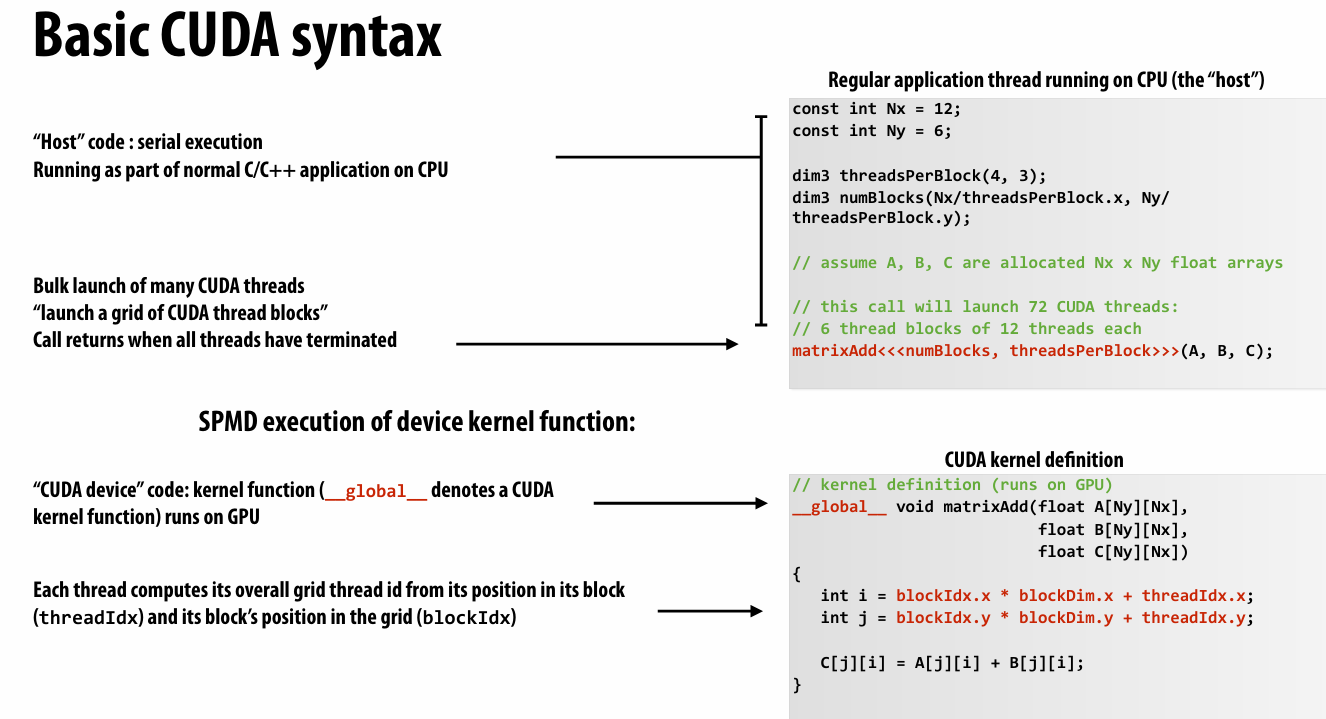
cuda thread的thread id 可以是多维的,这样天生更符合多维任务的习惯
一共num_blocks乘threadsperblock个
实际上host和device的地址空间是分开的,在现代机器上可以直接在gpu code中访问host指针,但实际实现可能涉及总线之类的,很慢
显示复制buffer的方法
float* A = newfloat[N]; // allocate buffer in host mem // populate host address space pointer A for (int i=0 i<N; i++) A[i] = (float)i; int bytes = sizeof(float) * N; float* deviceA; // allocate buffer in cudaMalloc(&deviceA, bytes); // device address space // populate deviceA cudaMemcpy(deviceA, A, bytes, cudaMemcpyHostToDevice);
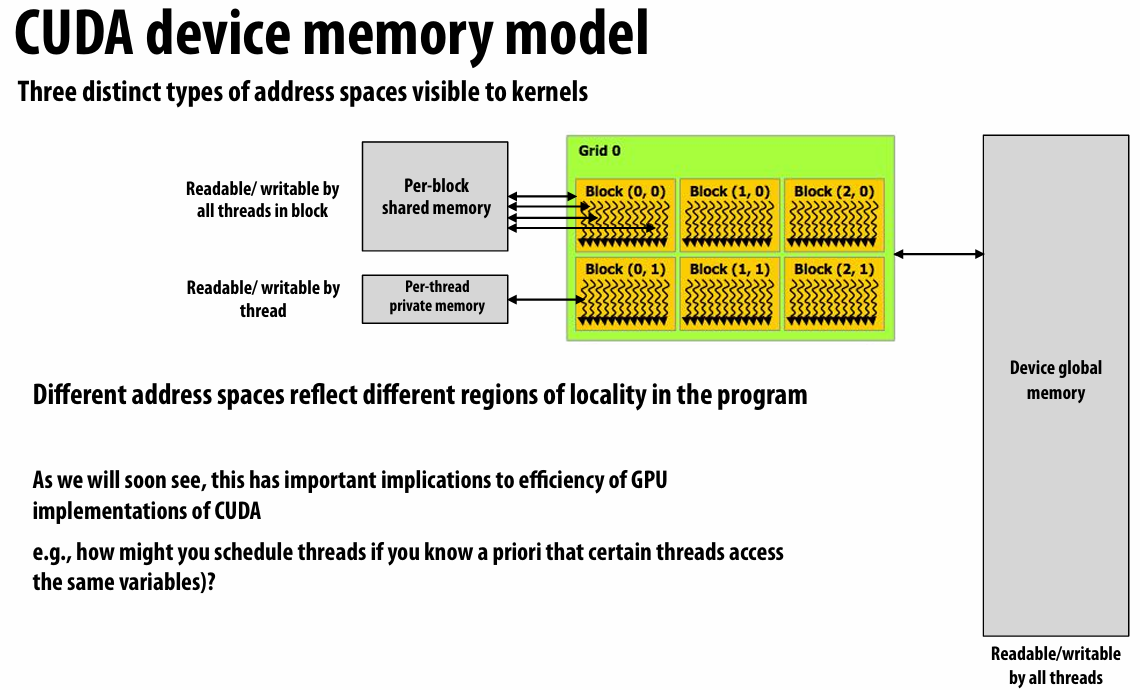
cuda的内存模型
这使得我们可以更好地利用cache hit
e.g 1D convolution
//每个线程都把该块会用到的变量加载到共享内存中(线程内不存在复用,但是线程之间存在复用) #define THREADS_PER_BLK 128 __global__ voidconvolve(int N, float* input, float* output){ __shared__ float support[THREADS_PER_BLK+2]; // per-block allocation int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local variable support[threadIdx.x] = input[index]; if (threadIdx.x < 2) { support[THREADS_PER_BLK + threadIdx.x] = input[index+THREADS_PER_BLK]; } __syncthreads(); } float result = 0.0f; // thread-local variable for (int i=0; i<3; i++) result += support[threadIdx.x + i]; output[index] = result / 3.f;
operating on the sequences of sequences:经常有两个层面的并行性
segmented scan:就是在输入序列的不同的分区上单独的scan(使用bool array 直接表示每个nested sequence 起始位置即可)
gather:将原序列中的对应位置处的元素收集起来构成新密集数组
scatter:将原序列中元素按照对应位置分散到稀疏数组
e.g1:
e.g2: output[index[i]] op=index[i]常规多线程得加锁,这样设计算法就不用
(sort之后的数组如果相邻index就可以认为是新的nested sequence)
Efficiently Evaluating DNNs
Overlapping communication and computation costs footprint(存储占用), since buffers for the data being
processing AND the data being transferred need to be maintained on chip.(为了实现边读边算,要双缓冲区)
cpu不能直接修改gpu上的内存!!!
解决方法就是直接调用cudamemset or cudamemcpy
前缀和&find_repeats
__global__ voidcalculate_up(int*output,int tow_d,int num){ int plus1=tow_d*2; int idx=blockIdx.x*blockDim.x+threadIdx.x; if(idx>=num)return; idx*=plus1; output[idx+plus1-1]+=output[idx+tow_d-1]; } __global__ voidcalculate_down(int*output,int two_d,int num){ int plus1=two_d*2; int idx=blockIdx.x*blockDim.x+threadIdx.x; if(idx>=num)return;//可能会有多的 idx*=plus1; int t=output[idx+two_d-1]; output[idx+two_d-1]=output[idx+plus1-1]; output[idx+plus1-1]+=t; } voidexclusive_scan(int* input, int N, int* result) { int formal_size=nextPow2(N);//处理原长度or补的 if(formal_size>N){ cudaMemset(&result[N],0,sizeof(int)*(formal_size-N)); cudaMemset(&input[N],0,sizeof(int)*(formal_size-N)); } for(int tow_d=1;tow_d<=formal_size/2;tow_d*=2){ int tow_dplus=2*tow_d; int tasknum=formal_size/tow_dplus; int blocknum=(tasknum+THREADS_PER_BLOCK-1)/THREADS_PER_BLOCK; calculate_up<<<blocknum,THREADS_PER_BLOCK>>>(result,tow_d,tasknum); } cudaMemset(&result[formal_size-1],0,sizeof(int));
for(int two_d=formal_size/2;two_d>=1;two_d/=2){ int two_dplus1=2*two_d; int tasknum=formal_size/two_dplus1; int blocknum=(tasknum+THREADS_PER_BLOCK-1)/THREADS_PER_BLOCK; calculate_down<<<blocknum,THREADS_PER_BLOCK>>>(result,two_d,tasknum); } } //计算方法,先标记再前缀和求下标 __global__ voidsetone(int*array,int formal,int*temp){ int idx=blockIdx.x*blockDim.x+threadIdx.x; if(idx>=formal-1)return; if(array[idx]==array[idx+1])temp[idx]=1; else temp[idx]=0; } __global__ voidcal(int*temp,int formal,int*output,int*size){ *size=temp[formal-1]; int idx=blockIdx.x*blockDim.x+threadIdx.x; if(idx>=formal-1)return; if(temp[idx]!=temp[idx+1]){ output[temp[idx]]=idx; } } intfind_repeats(int* device_input, int length, int* device_output){ //cuda kernel must be void,the way to return value is to pass pointer between device and host int rounded=nextPow2(length); int *temp=nullptr; int size=0; int*h_size=&size; int*d_size=nullptr; cudaMalloc((void**)&d_size,sizeof(int)); cudaMalloc((void**)&temp,rounded*sizeof(int)); int blocksize=(rounded+THREADS_PER_BLOCK-1)/THREADS_PER_BLOCK; setone<<<blocksize,THREADS_PER_BLOCK>>>(device_input,rounded,temp); exclusive_scan(temp,rounded,temp); cal<<<blocksize,THREADS_PER_BLOCK>>>(temp,length,device_output,d_size); cudaMemcpy(h_size,d_size,sizeof(int),cudaMemcpyDeviceToHost); cudaDeviceSynchronize(); cudaFree(temp); cudaFree(d_size); return size; }
render
warning 也得看!!!(变量是在host or device(__constant__表示device特殊位置))
cuda debug
//使用以下宏来wrap function call #define DEBUG
#ifdef DEBUG #define cudaCheckError(ans) { cudaAssert((ans), __FILE__, __LINE__); } inlinevoidcudaAssert(cudaError_t code, constchar *file, int line, bool abort=true) { if (code != cudaSuccess) { fprintf(stderr, "CUDA Error: %s at %s:%d\n", cudaGetErrorString(code), file, line); if (abort) exit(code); } } #else #define cudaCheckError(ans) ans #endif
算法流程
Clear image for each circle update position and velocity for each circle compute screen bounding box for all pixels in bounding box compute pixel center point if center point is within the circle compute color of circle at point blend contribution of circle into image for this pixel