ispc gang is actually implemented by SIMD
写的时候像是SPMD(多个逻辑线程),但是优化的时候要考虑它实际上是SIMD
通过programindex,programcount等底层暴露才能在需要的时候优化性能
task:实际上是一个线程池(固定八个线程取任务来做)
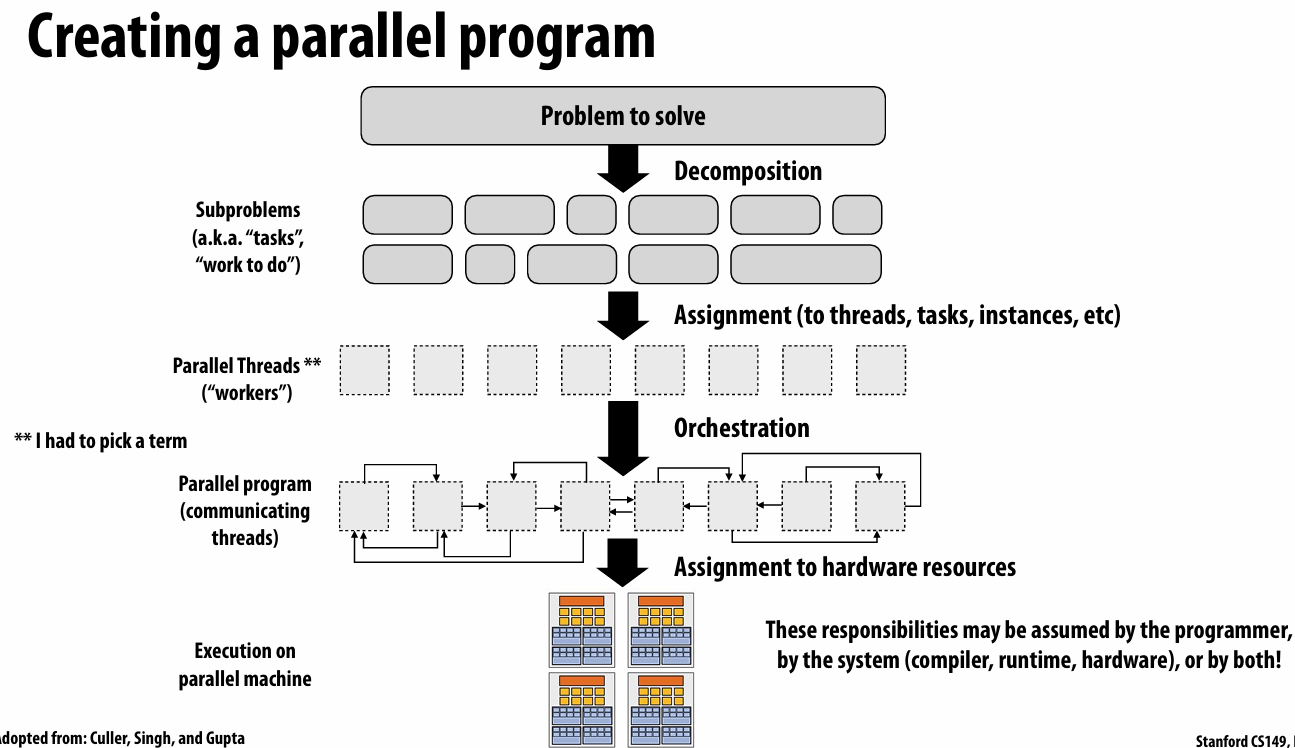
Case study on thought process of writing and optimizing a parallel program
区分:硬件线程和操作系统线程(后者需要context switch,开销非常高,后者是一套处理单元对应多个状态,直接切换,开销低)
a small part of sequential can largely limit the speed up
key of decomposition is to identify independencies(often by programmer)
assignment:assign task to thread,vector lane etc(workload balance,reduce communication)
tips:always implement the simplest solution and measure performance to determin the next
balancing the work load
static assignment:assign didn’t depend on dynamic behaviour
简单,同时无需进行分配,可以减少开销(很多时候通信开销也可以削减)
实际上在运行时间大概可预测的时候(统计意义上的预测也行)很有效
semi-static:运行一段时间后根据结果再进行静态分配
dynamic assignment:to achieve good load balancing
可以视为使用了一个巨大的任务队列,每个进程挨个去取任务,自然而然有关于队列信息的进程间通信开销
任务划分的权衡:任务划分的更细就有更多的灵活性以确保负载均衡,但是要同步队列状态可能导致极高的通信开销(lock and unlock)
也有可能就是有个别任务时间极长:一种方法是先分配长时间的任务(sorted)
constint N = 1024; constint GRANULARITY = 10; // assume allocations are only executed by 1 thread float* x = new float[N]; bool* prime = new bool[N]; // assume elements of x are initialized here LOCK counter_lock; int counter = 0; while (1) { int i; lock(counter_lock); i = counter; counter += GRANULARITY; unlock(counter_lock); if (i >= N) break; int end = min(i + GRANULARITY, N); for (int j=i; j<end; j++) is_prime[i] = test_primality(x[i]); }
之前谈的大多是数据并行性(data parallelism:对不同数据进行相同操作)
另一种表示并行的方法:树
e.g:快排,其天然可以并行分治部分,由于递归可以带来很高的并行性
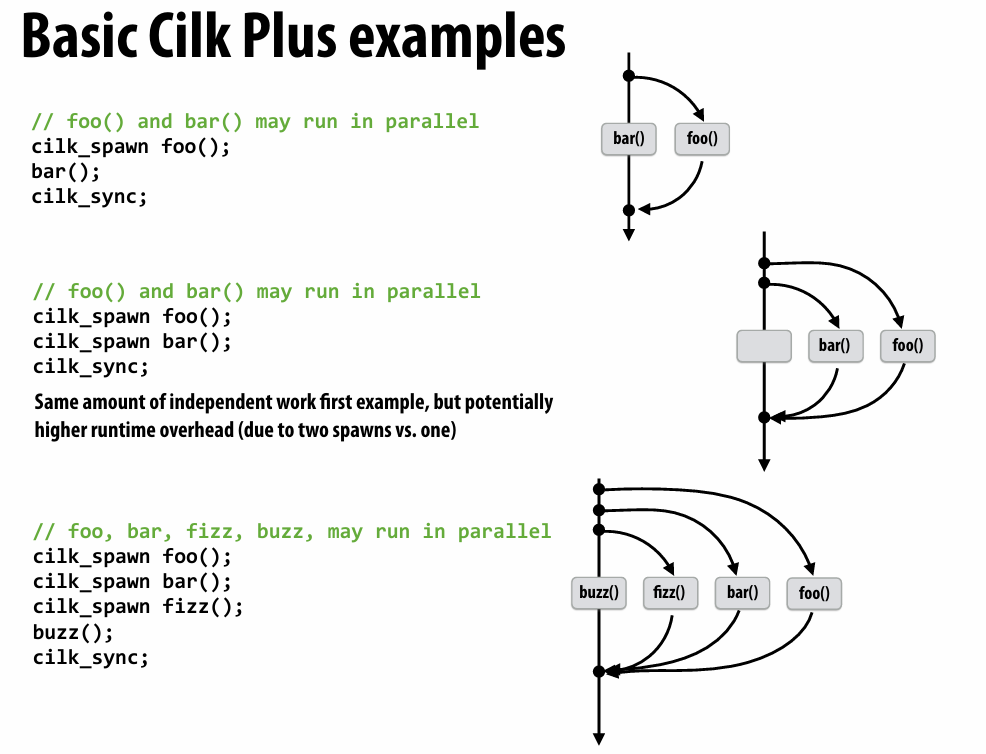
notice:the cilk is just the abstraction,for implementation,complete sequential and complete parallel are acceptable
术语:child(spawn出来的),continuation(spawn后面的)
实际上有两种策略(run child first and run continuation first)
continuation first:
如果只是单纯for loop创建一堆任务,BFT of call graph
caller spawn all thread before any one executed
child first:
caller only create one thing for stealing
depth first traversal of call graph
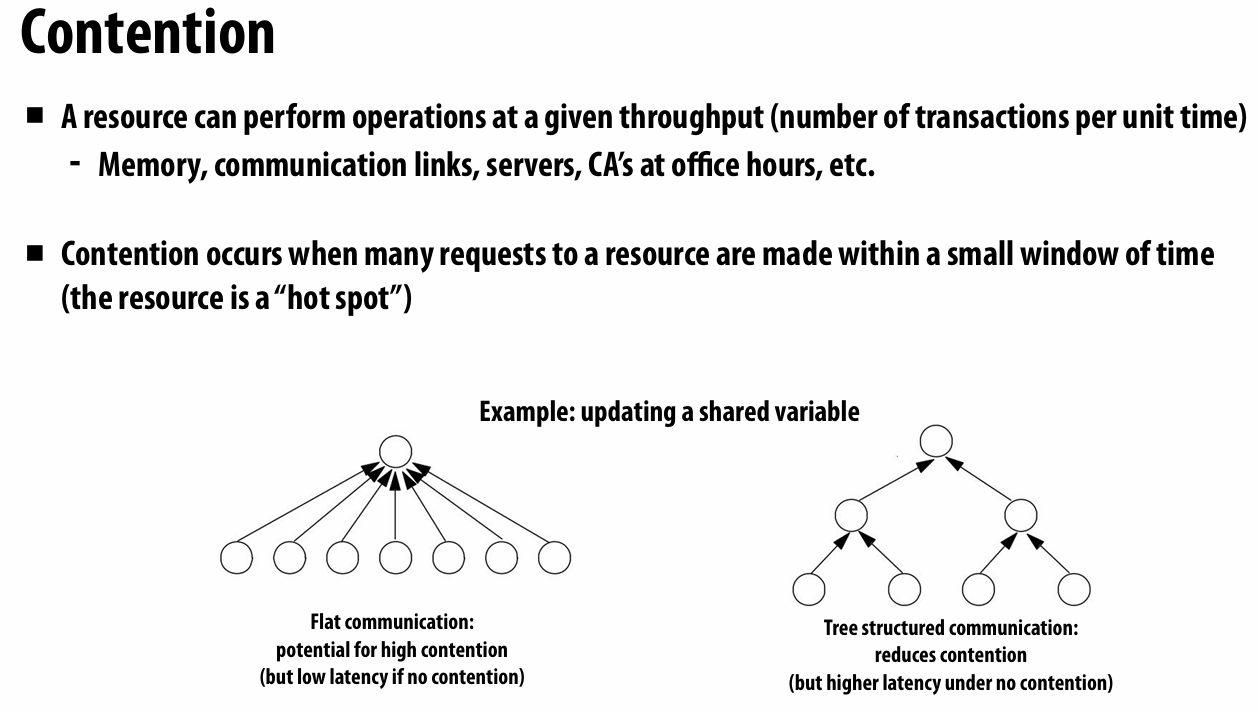
optimization:locality,communication and contention
共享地址空间(像是一个公告板,软件实现简单,硬件实现相当复杂)
另一种通信机制:message passing
更像是送邮件,不公开,由发送者和接收者之间
二维网格示例:每个线程需要存储比其负责更新的点更多的点以用于更新
通信全部体现在send and receive(没有共享,每个都有副本所以不用互斥锁,而barrier是隐含在里面)
synchronize(blocking) send and receive
send 之后要接到对方的信息才return, receive 之后 送出接收到的信息再return
这样之前的实现就会导致死锁(大家都在等别人送回来)
asynchronize(non-blocking) send and receive
调用之后立即返回一个句柄,不立即发送或接受(异步),在要确认接受/发送的情况下可以检测句柄
arithmetic intensity:
amount of computation/amount of communication
inherent vs. artifactual communication
inherent communication:communication that must occur in parallel algorithm
way to reduce:in the 2d grid example
arithmetic intensity is roughly 面积除以周长(所以按正方形来block可能就会比较好)
Artifactual communication: all other communication