
csapp_proxylab
networkprogrammingP1

- lowest level:ethernet segment(以太网)
- 一个房间或者一栋建筑这种,一组的host通过线连接到hub的port
- 每个有一个独有的48位地址(MAC address),以chunk为单位发送数据

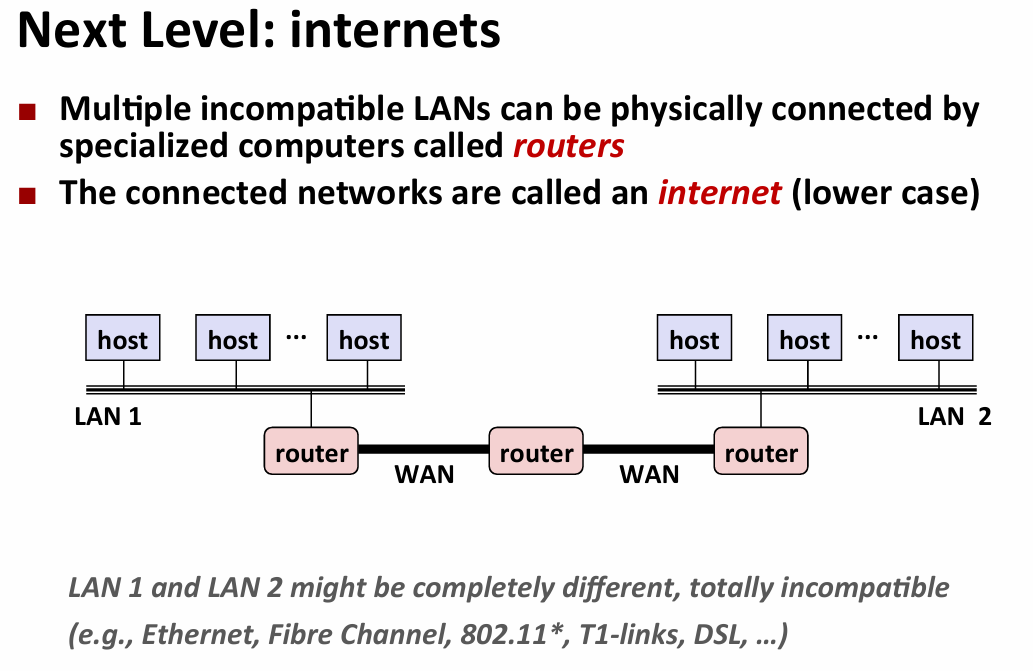
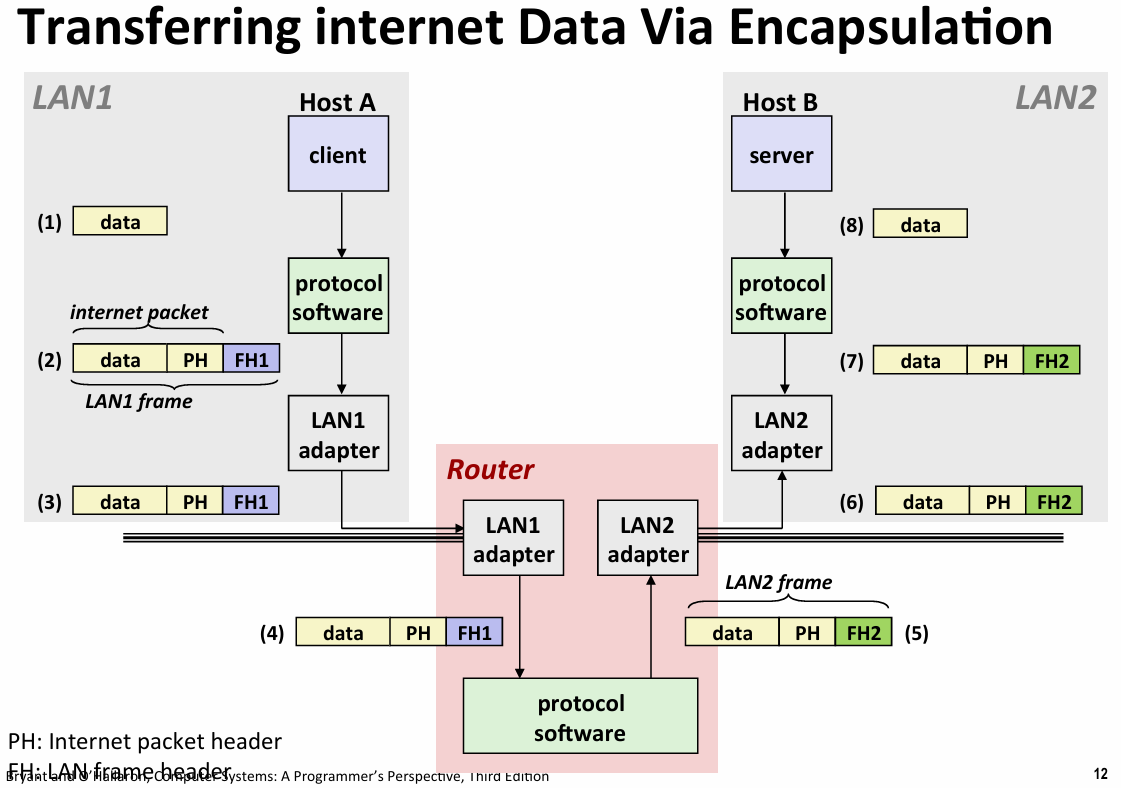
- 在不同标准的设备之间通信:protocol software run on the rounter and host(提供命名规范和行为机制)
- ipv4:32位大端法存储,这被映射到网址(域名)
- 三级域名:第一级(.com,.edu等)第二级(mit,berkeley等)第三级(www.等)
- DNS(domain naming system)
- 每个主机都有自己的局部域名localhost 127:0:0:1
- 常见命令:nslookup\hostname
- 域名和地址之间不是一一对应的关系,大型网站全球都有DNS所以可能不一样,甚至可能有效的域名不指向任何地址
- connection:client and server use it to send message
- socket:endpoint of a connection ipaddress:port
- port:16 bits integer identify different process(分为临时端口和wellknown,mapping at /etc/services)
- a connection is identified by socket pair
- socket:
- for kernal it’s the endpoint of a connection
- for application it’s a file descriptor
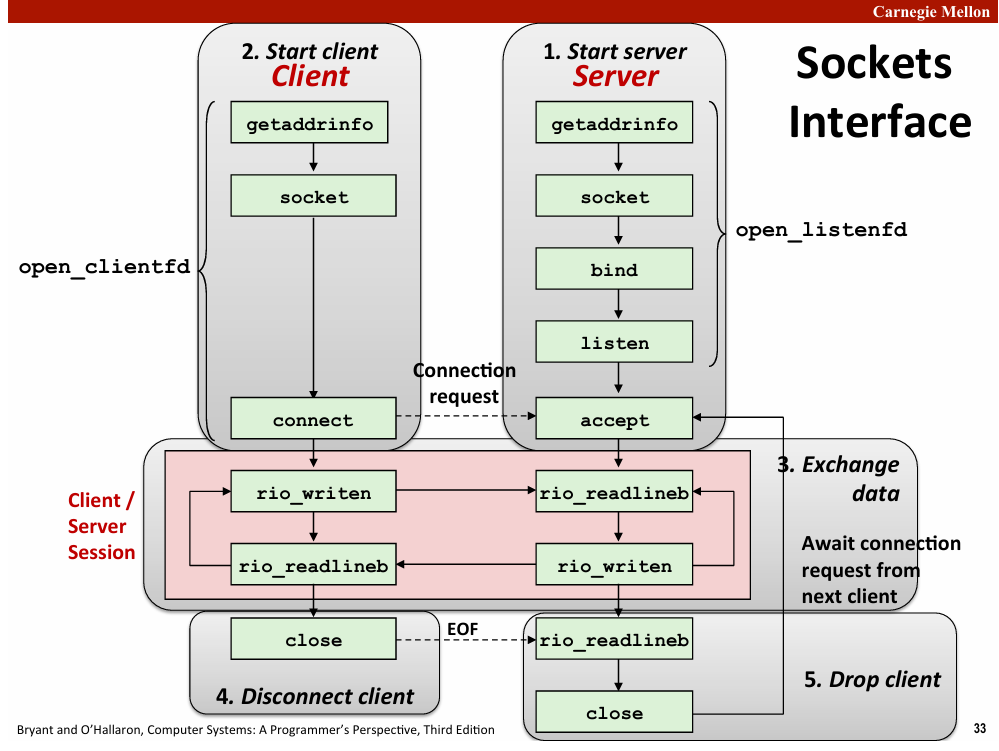
int socket(int domain,int type,int protocol)//return the fd
int bind(int sockfd,SA *addr,socklen_t addrlen)
server call to tell the kernal associate socket address with file descriptor
int listen(int sockfd,int backlog)
tell the kernal that this descriptor is used by server(default see as client)
int accept(int listenfd,SA *addr,int *addrlen)
server ready for request from client,return a connected descriptor
int connect(int clientfd, SA *addr, socklen_t addrlen);

- host and service convertion

为了处理多对多的映射关系,采用链表
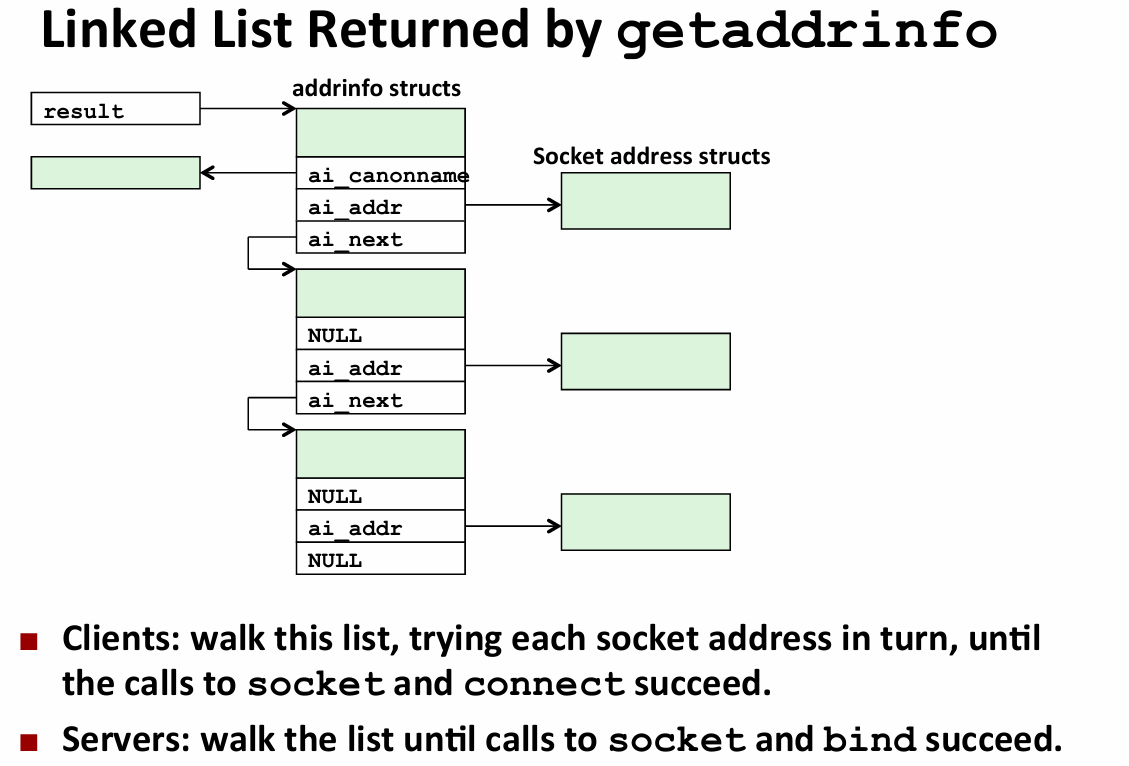

getnameinfo:inverse of the getaddrinfo
networkprogrammingP2
//an example to get the ip address |
- the code for the client to establish a connection
int open_clientfd(char *hostname, char *port) { |
- code for the server to prepare
int open_listenfd(char *port) |
- 服务器端:struct sockaddr_storage//enough room for any address
web server basic
http(hypertext transfer protocol):web content(语义)
tcp:stream(完整字节流)
ip:datagrams
content:a sequence of bytes with associated MIME(multipurpose internet mail extensions) type
url(universal resource locator):协议,服务器,端口,文件的位置
http request:request line+header
http response:response line+header+content
- GET /cgi-bin/env.pl HTTP/1.1(cgi-bin:表示要动态内容,要求运行程序)
- http://add.com/cgi-bin/adder?15213&18213 ?开始以&分割的参数列表
- 服务器设置环境变量为参数后启动子进程运行程序,dup2写回去
concurrent programming
- some classical problems with concurrent
- races:多个进程的执行结果取决于调度(父进程可能在加入子进程的时候子进程已经结束,意外的共享状态)
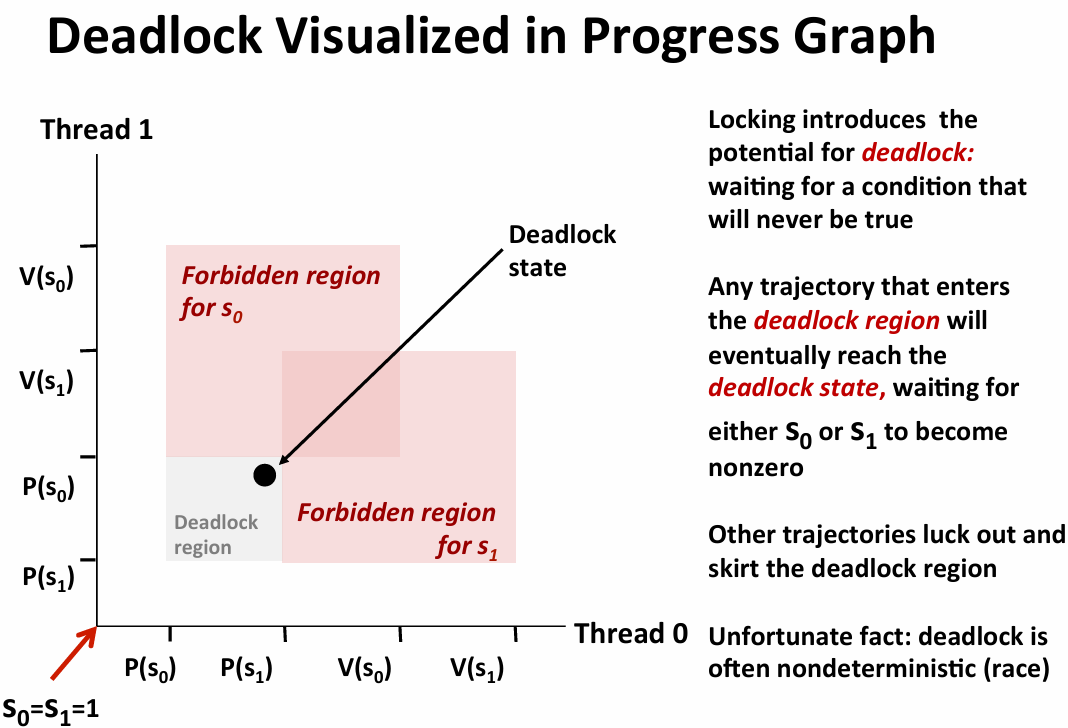
- deadlock:等待永远不会发生的情况
- starvation:总是调度一个进程,另一个进程调度不了
- iterative web server:client 的read环节堵塞,一次只能处理一个
method

- approach1:spawn seperate process for each client
- must reap the children ,parent close the connfd,children close listen fd
- 简单,开销高
- approach2:

- 开销小,单线程易于调试,但是难以利用多核优势
- 难点:如何解决可能没输完的request header,
- approach3:
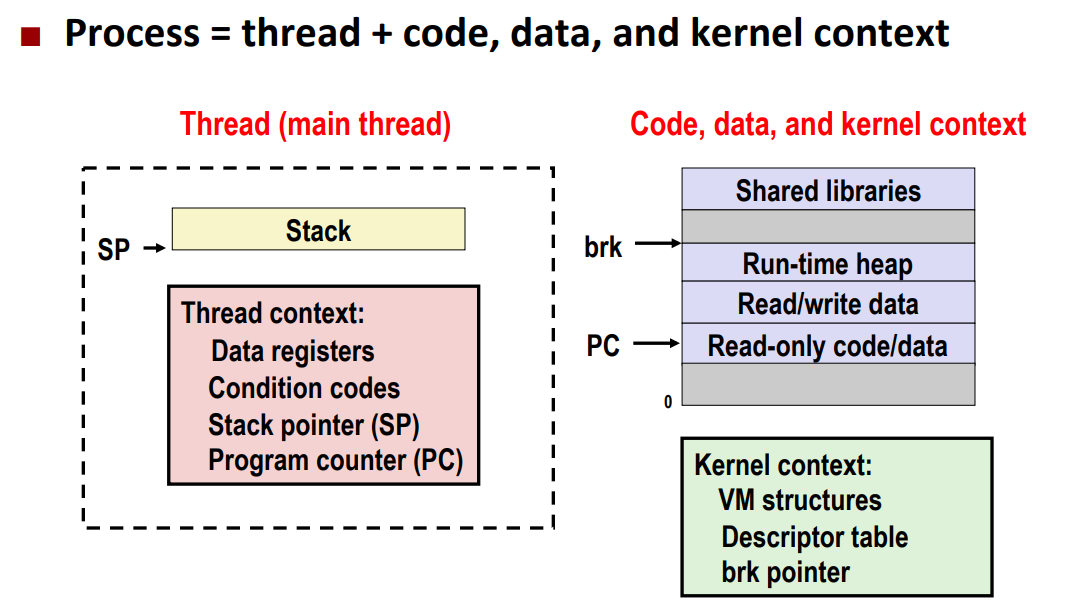
- process=process context(program+kernal)+code+data+stack
- thread=thread context(program context+stack)+code+data+kernal context
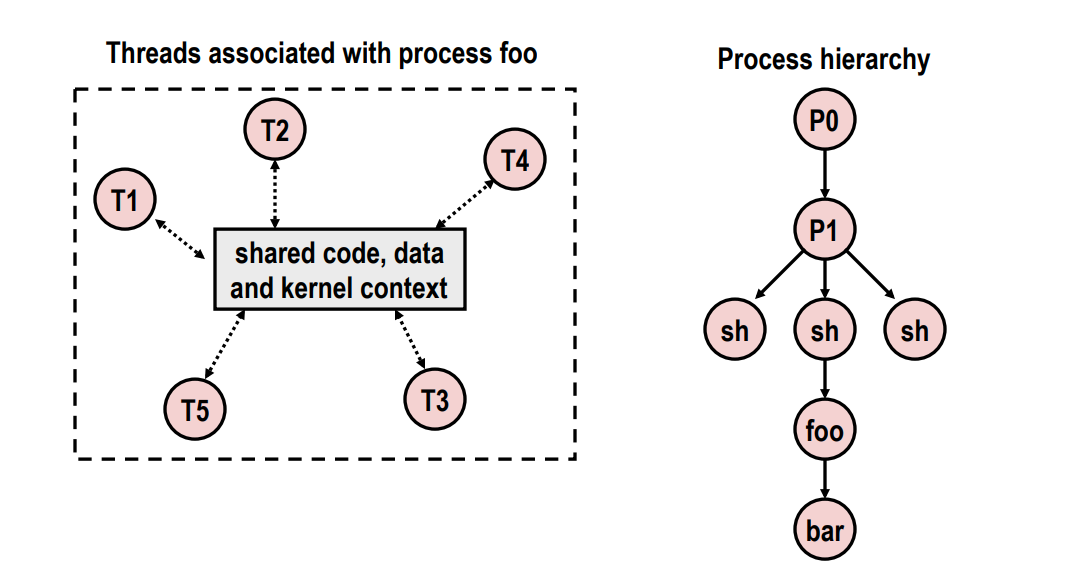
- (相比顺序结构可以视为线程池)
- threads:

int main(int argc, char **argv) |
如果不malloc:可能在子线程程开始之前主线程又读了一个,此时该变量被修改
sync-basic
- def: a variable is shared if and only if its instance is referrenced by mutiple threads(not just the global and private)
- threads memory model:
- conceptually,multithreads run in the context of a single process
- but in fact the stack of a thread can be visited by other thread(e.g:by the global pointer point to local stack)
- mapping memmory to reference
- global:declared outside the function,vm maintains only one
- local:non-static variables inside the function,each thread stack contains one
- local static:vm maintains only one
example
- volatile:该关键字声明的变量会禁止永久保存在寄存器中(每次要算都是从内存取出再写回去)
- 如果遇到两个线程更新一个volatile的全局变量可能出问题(load->update->save)
- e.g:load1->update1->load2->update2->save1->save2(汇编才比较好看出来)
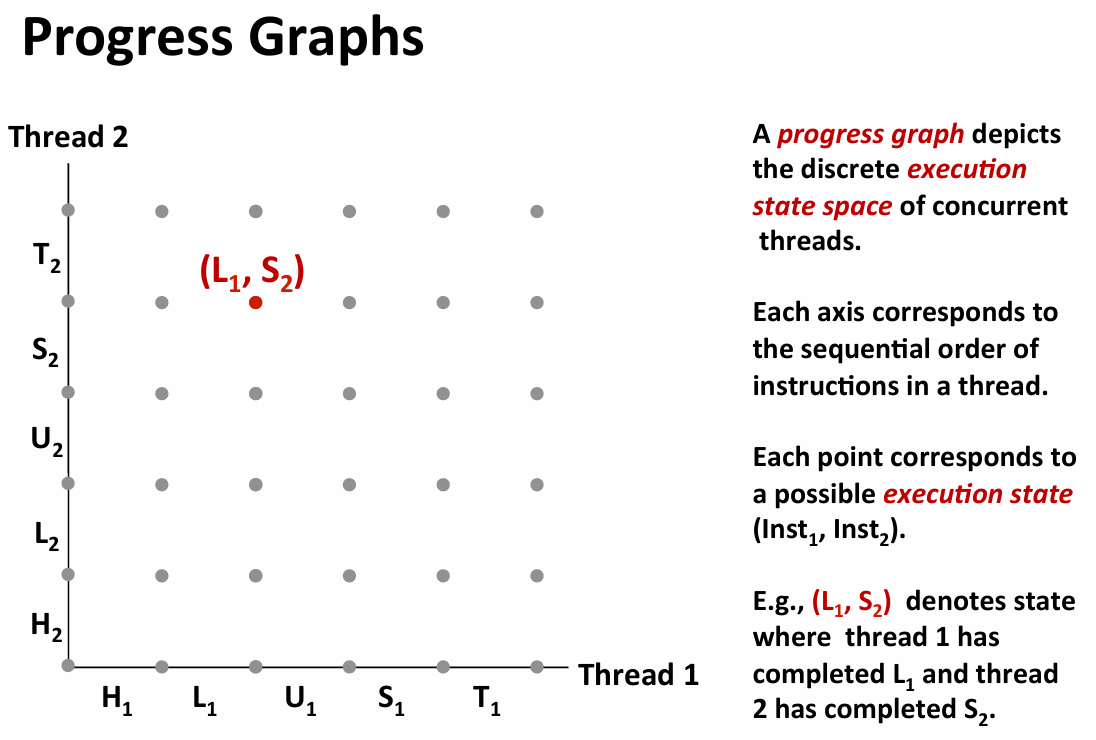
- trajectory:a sequence of legal states(safe iff it doesn’t go into the interleaved region)
- the three state above are the critical section it should not be interleaved
synchronize
to avoid the above,we need to make sure mutual exclusive access to the critical region
solution:semaphores(信号量)
- non-negative global integers manipulated by P and V
- P(locking mutex):
- if not zero,decrement and return immediately(test and decrement combined atomically)
- if zero,block current thread until non zero and restart by V,after restart,decrement and return the control
- V(releasing/unlocking mutex):
- increment atomically
- if existing blocked by P thread,restart arbitrarily one.
basic idea:init it to 1,P right before critical region ,V right after critical region
- terminology:binary semaphores(bs) mutex:bs used for mutual exclusion holding means locked
sync-advance
two example
producer-comsumer problem
producer thread and comsumer thread share a buffer,producer wait for an empty slot,comsumer wait for an item
very common in GUI(graphic user interface)
solution:
- three semaphores:mutex(ensure exclusive access to shared buffer),slot,item
- wait for available(slot or item),lock the buffer,operation,unlock,update semaphores
- if multi-core execute the P same time,kernal will serialize them
reader-writer problem
there is no need to block the reader for reader makes no change to the data
- the solution favor reader:reader get priority over writer,it doesn’t wait
int readcnt=0; |
- also exist favor writer
prethreaded
create and destroy thread depend on demand requires overhead
solution:create prethreaded thread pool
two ways to init buffer
- first:init just in the main thread
- second:
static pthread_once_t once=PTHREAD_ONCE_INIT; Pthread_once(&once,init)- the variable actually will be defined in each thread,but only once will the init execute
thread safe
a function is thread-safe iff it always produce correct result when calling from multi-thread
- class 1:don’t protect shared variables
- use P and V,but will slow down
- class 2:functions keep state cross invocation
- different schedule can produce different result sequence
- maintain local variables
- class 3:return a pointer to a static variable
- just the race,the invocation in-between return and assign can wrong
- way1:让调用者提供缓冲区
- way2:锁保护下读并复制(不用改库函数)
- class 4:call thread-unsafe function
a function is reentrant iff it doesn’t access shared variables(just a subset of thread-safe function)
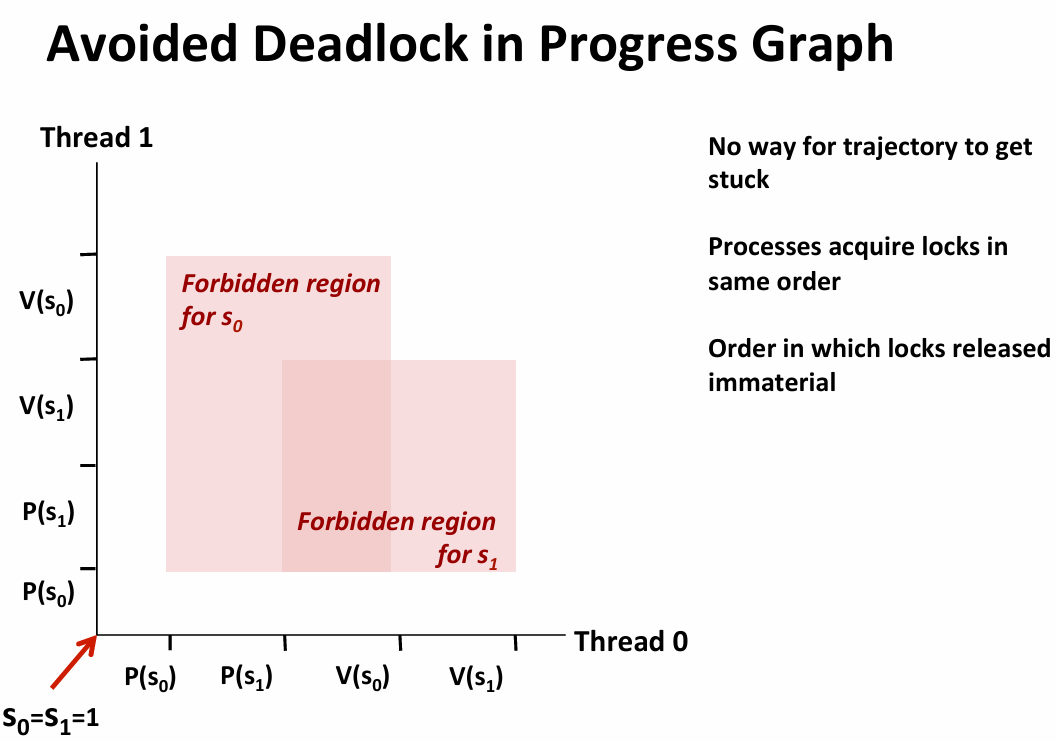
avoid dead lock:just modify the order of acquire the resource
proxylab
Pthread_detach():分离线程,自动回收资源Signal(SIGPIPE,SIG_IGN//直接丢弃该信号的宏):防止向已关闭的链接写入的操作导致触发信号终止进程- HTTP请求
- 默认1.1要求持久化链接
//request header |
解析请求:前缀+host+port+path
thread-level paralism
multicore:multiple seperate processors on a single chip
hyperthreading:efficient execution of multithread on a single core
- typical multicore chips have own L1 and L2 cache and shared L3 cache
- out-of-order processor structure:
- instruction control has a decoder to convert instructions to stream of operations
- a single core has many function units,each execute different task
example
sum 0 to n-1
- reminder:the operation on semaphores are quite expensive
- a good practice:every thread accumulate on a local variable and put them in global arrays to be sum up
- avoid race and manipulate numbers from memory
some concept:
speed up:
efficiency:
sort
- parallel quick sort:
if N<Nthresh,do sequential quick sort//avoid too fine grained paralism |
- some lesson:
- have different strategies and experiment on it
- do not sychronize in the inner loop
- be aware of Amdahl’s law
memory consistency
- principle:sequential consistency(the overall effect should be consistent with single thread)
- a.k.a:the arbitrary interleaving
- how:snoopy cache
- tag the data both in the cache and the memory
- invalid\shared(readonly)\exclusive(writeable copy)
- when need a e-tagged data,seek in cache and set it shared


